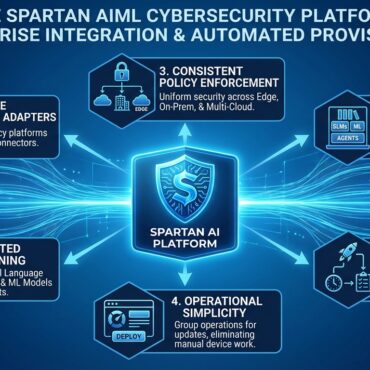
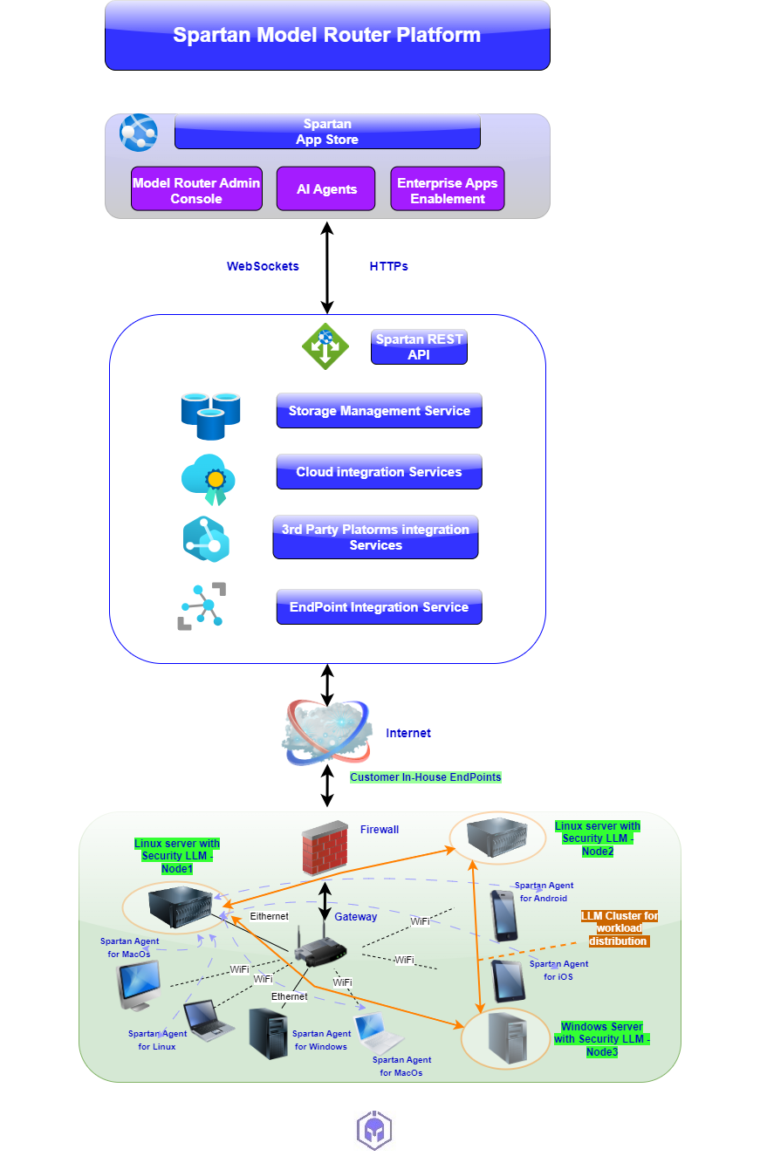
Redefining Trust at the Edge The Spartan AI platform utilizes four primary approaches designed specifically for the unique challenges of Edge-AI environments: ✅ Ease of Integration: The platform is designed for “plug-and-play” capability, allowing it to integrate seamlessly into existing enterprise environments. ✅ Continuous On-Chip Machine Learning and Inference: Recognizing that threats [...]
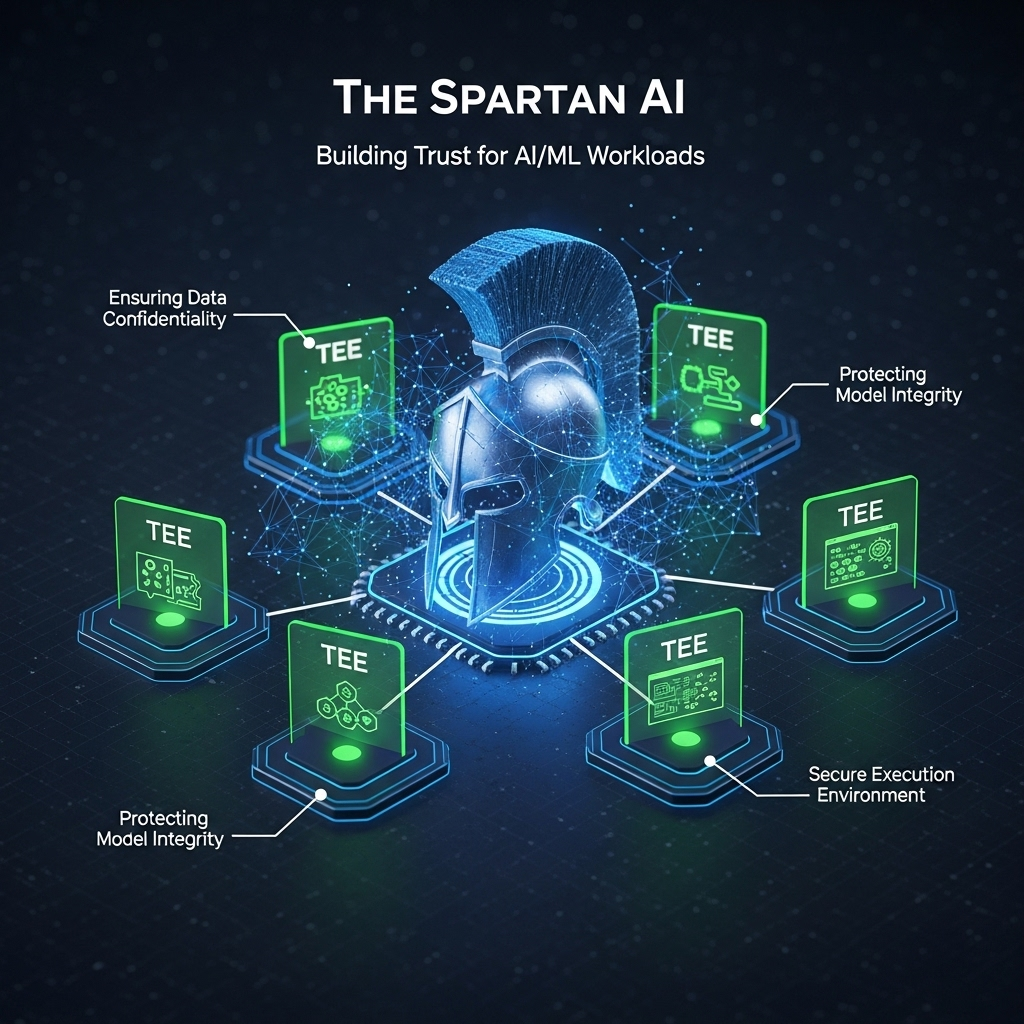
We’ll discuss the growing field of Confidential Computing (CC), focusing on hardware-based security for artificial intelligence (AI) and virtual machine (VM) workloads. We’ll explain how The Spartan AI Platform and technologies like AMD SEV-SNP, Intel TDX, and Arm CCA (Confidential Compute Architecture) create Trusted Execution Environments (TEEs) to protect data and code in use, even from privileged software like hypervisors.
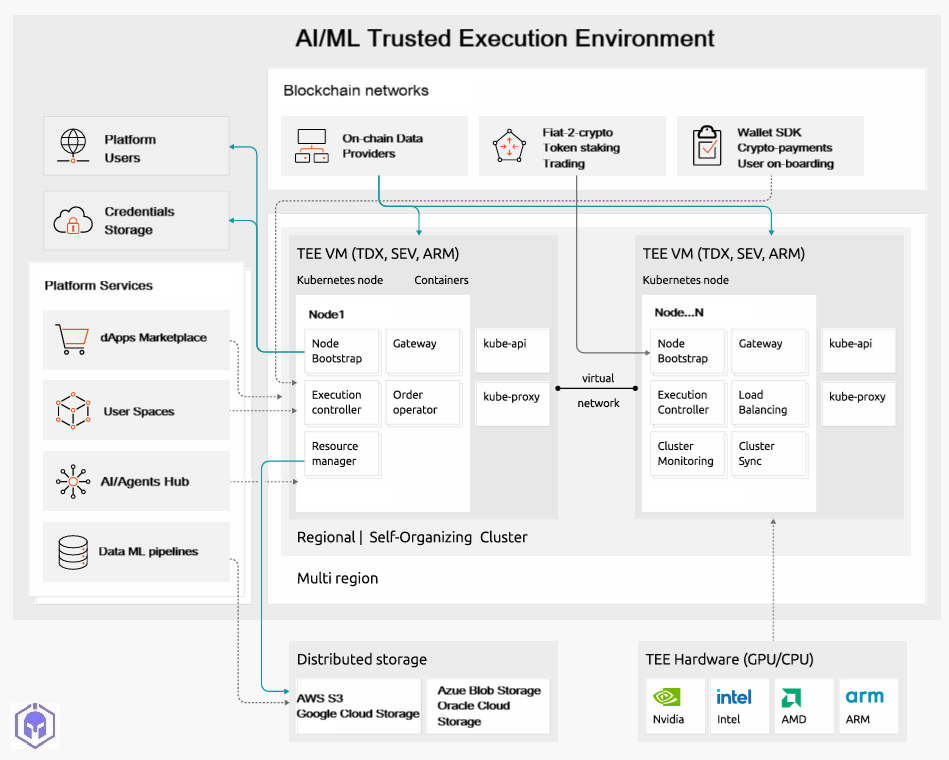
Based on a real use case for building a product for Distributed Apps for cryptocurrency market services like trend analysis, staking and trading, we evaluate step-by-steps components for building a trust-worthy platform.
That use case facilitates secure AI marketplaces, Private AI usage emphasizing the mitigation of risks like data theft, intellectual property (IP) exposure, and data poisoning in AI development and deployment. Below is a top-level overview of the use case platform.
We’ll provide a technical overview of confidential Trusted Execution Environments (TEEs) and details how these architectures, such as AMD SEV-SNP, Intel TDX/SGX, and Arm CCA, are leveraged to secure modern AI/ML workloads with the help of The Spartan AI orchestration platform.
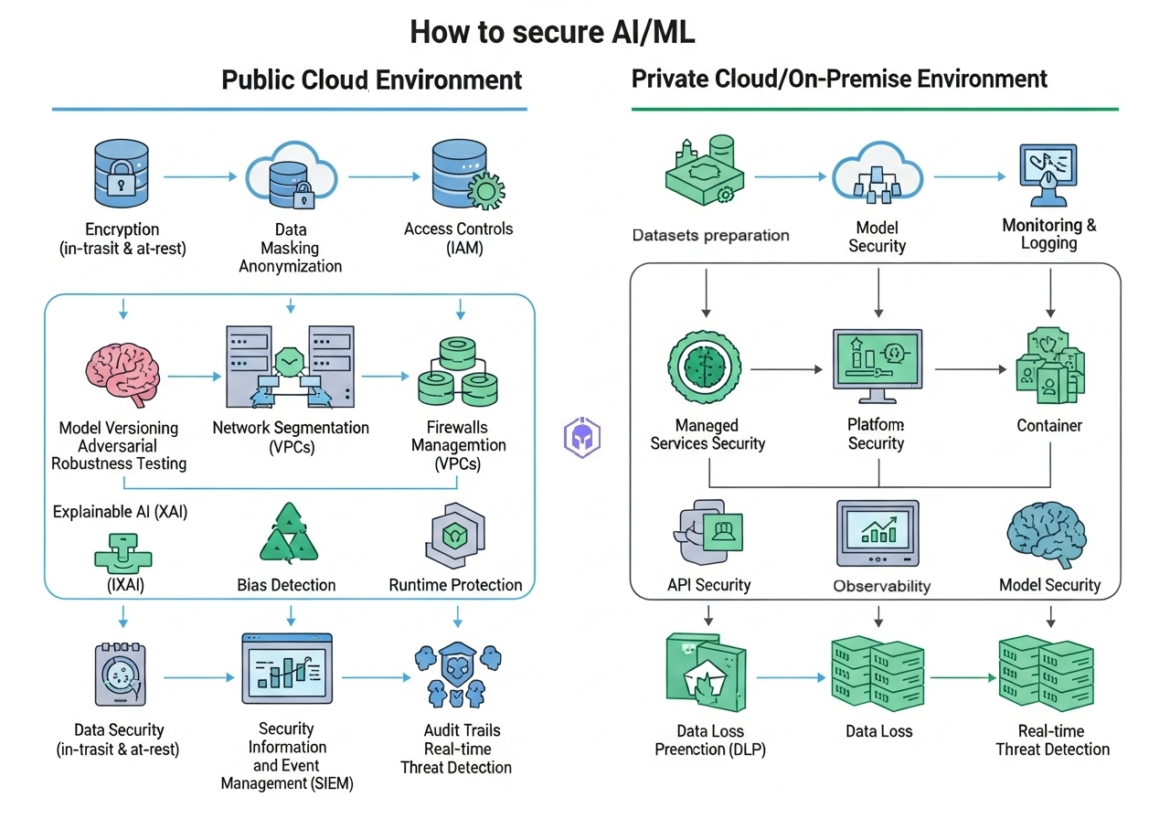
Confidential computing is a pivotal technology that transforms how sensitive data is handled in AI and other high-stakes fields. Confidential Computing is defined as the protection of data in use, achieved by performing computation in a hardware-based secure environment designed to shield portions of code and data from access or modification, even from privileged software.
The foundation of confidential computing is the Trusted Execution Environment (TEE). A TEE is a hardware-based security feature that isolates computations, preventing unauthorized access and tampering, even from the operating system or the physical hardware owner. TEEs address critical issues such as intellectual property protection, data leakage, and unauthorized access.
As AI adoption grows, companies frequently face security concerns, including intellectual property (IP) exposure, data leaks, and unauthorized access. These issues often limit collaboration and restrict the scalability of AI solutions. By ensuring that sensitive data and AI processes remain secure during execution, confidential computing addresses these constraints. Confidentiality and integrity during AI processing are essential, especially as AI increasingly depends on cloud and distributed computing, where the risk of infrastructure attacks, malicious actors, or compromised nodes can expose sensitive models and computations. TEEs help ensure that data remains secure even while actively in use across the AI pipeline—during model training, fine-tuning, and inference.
The modern confidential computing landscape features robust hardware architectures from major vendors, each providing unique capabilities for isolating and protecting execution environments.
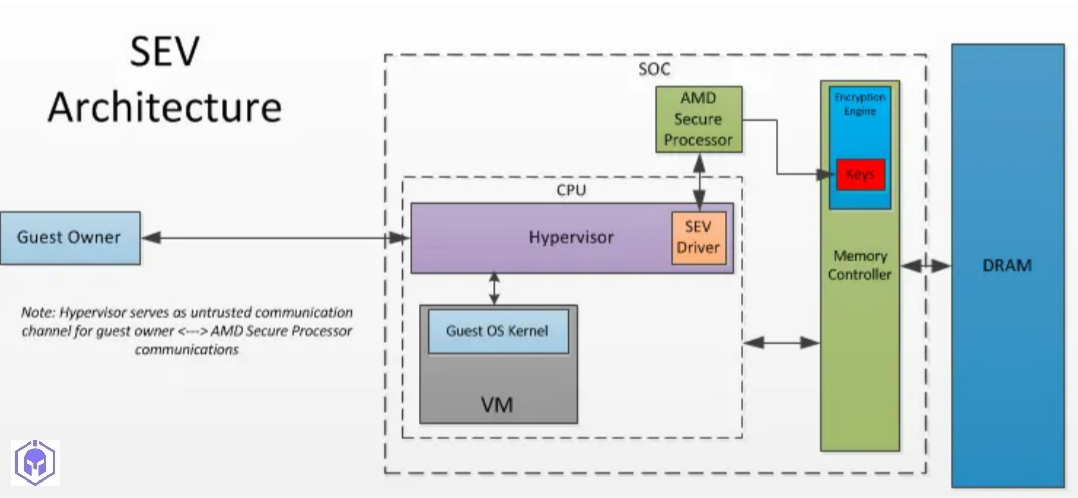
AMD SEV-SNP
AMD introduced Secure Encrypted Virtualization (SEV) in 2016 as the first x86 technology designed to isolate Virtual Machines (VMs) from the hypervisor. SEV works by using main memory encryption, assigning a unique AES key to each VM to automatically encrypt its in-use data. When a component like the hypervisor attempts to read a guest’s memory, it only sees the encrypted bytes.
SEV-SNP (Secure Nested Paging) is the next generation, building upon existing SEV and SEV-ES (Encrypted State) functionality. SEV-SNP adds strong memory integrity protection designed to prevent malicious hypervisor-based attacks, such as data replay, memory re-mapping, and data corruption, in order to create an isolated execution environment.
Key mechanisms in SEV-SNP include:
Integrity Guarantee: The basic principle of SEV-SNP integrity is that if a VM reads a private (encrypted) page of memory, it must always read the value it last wrote.
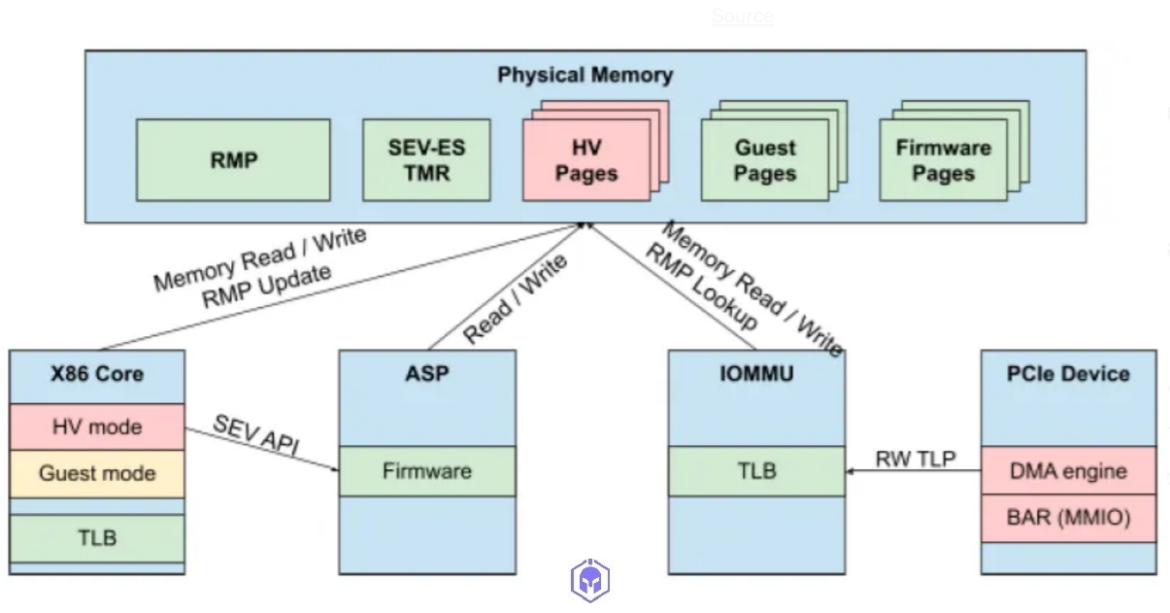
2. Reverse Map Table (RMP): The RMP is a system-wide data structure containing one entry for every 4k page of DRAM. It tracks the owner (hypervisor, specific VM, or AMD-SP) of each page, and controls access so that only the owner can write to that page. The RMP is used to protect against Replay Protection, Data Corruption, and Memory Aliasing attacks.
3. Page Validation: This mechanism addresses the Memory Re-Mapping threat by ensuring that every guest page maps only to a single page of physical memory at a time. A guest uses the new PVALIDATE instruction to validate a page, which sets a Validated bit in the RMP entry. If a malicious hypervisor attempts to remap the guest page to a different physical address, the guest receives an exception because the Validated bit is clear for the new physical address.
4. Threat Model: Under SEV-SNP, the AMD System-On-Chip (SOC) hardware, the AMD Secure Processor (AMD-SP), and the VM itself are treated as fully trusted. All other CPU software components (BIOS, hypervisor, device drivers) and PCI devices are treated as fully untrusted.
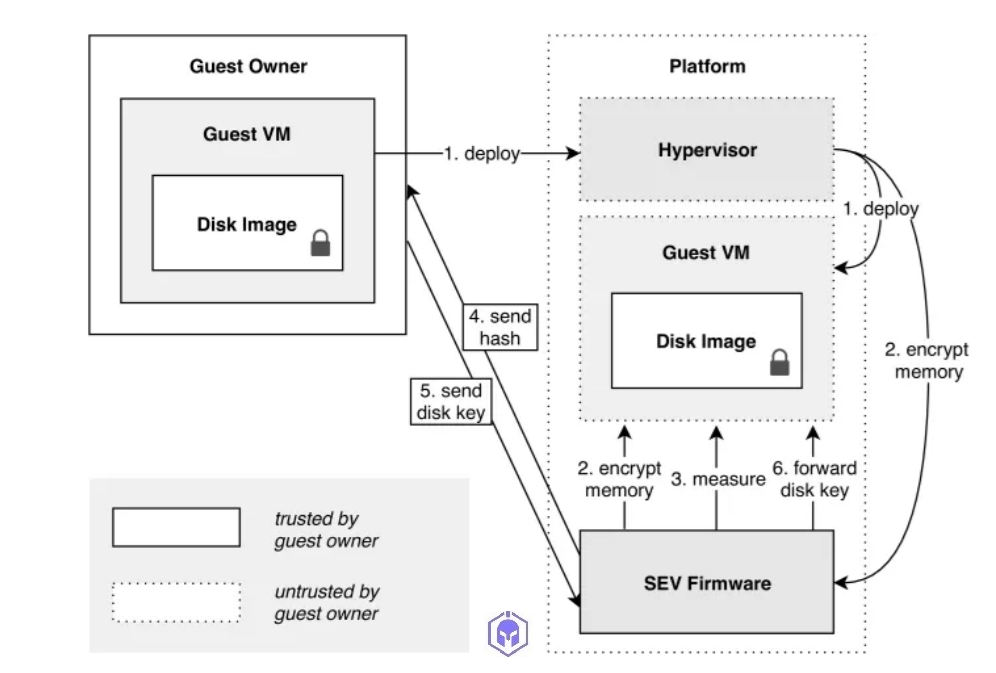
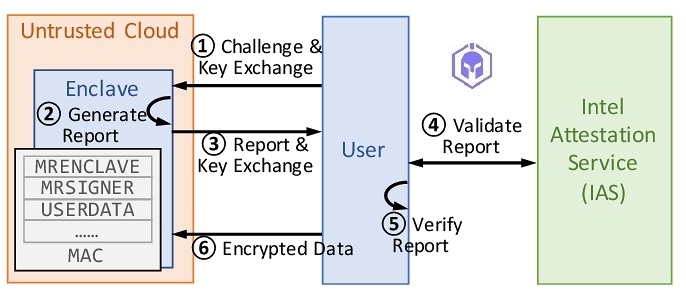
5. Attestation: To establish trustworthiness between guest VM owner and cloud based confidential computing platform/VM instance, guest owner deploys its confidential payload.
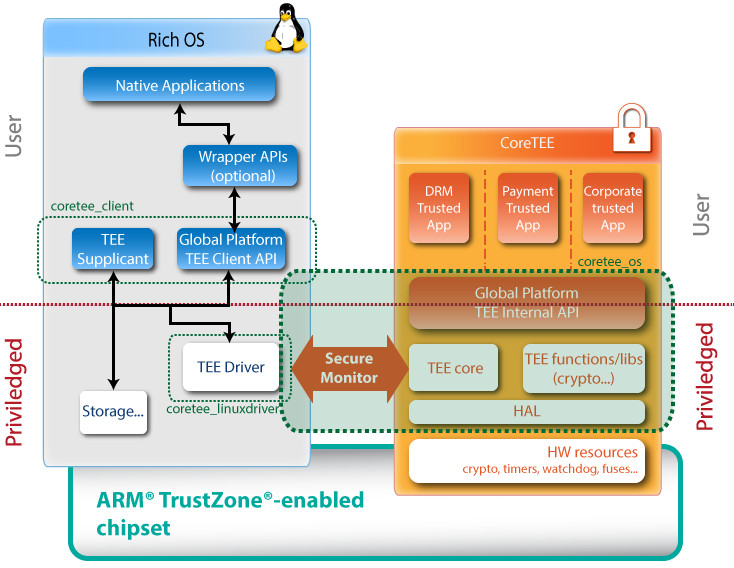
Intel TDX/SGX
Intel’s Confidential AI capabilities rely on its Confidential Computing products, Intel® Trust Domain Extensions (Intel® TDX) and Intel® Software Guard Extensions (Intel® SGX), which use a hardware-based TEE to protect sensitive data and applications.
For deployments requiring an accelerator or GPU, Intel is introducing Intel® TDX Connect to provide a secure channel for communicating directly with PCIe-compliant accelerators from any vendor. Currently, Intel supports the secure use of Nvidia accelerators using bounce buffers—a software-based solution that provides core functionality ahead of the availability of the full hardware-based Intel TDX Connect.
Intel SGX, which implements enclaves, isolates code and data within an area of secure memory called the Processor Reserved Memory (PRM). Since the secure memory size in SGX enclaves is often small relative to deep learning model requirements, SGX provides secure paging mechanisms to encrypt and swap memory pages between secure and main memory.
Arm CCA
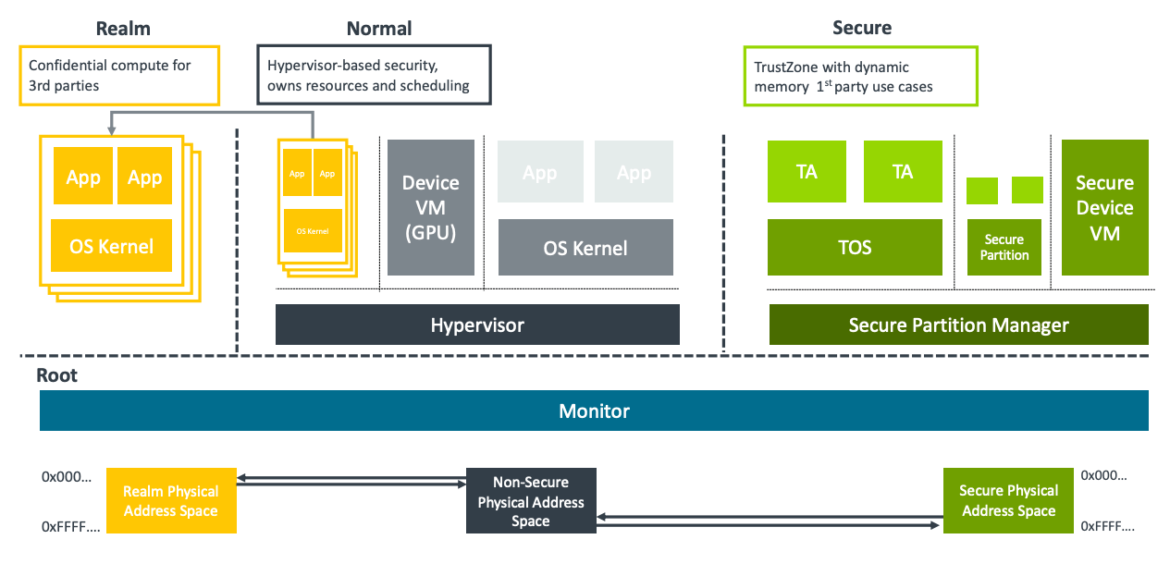
The Arm Confidential Compute Architecture (Arm CCA) was introduced as a supplement to Armv9.2-A. Arm CCA is designed to protect data and code wherever computing happens.
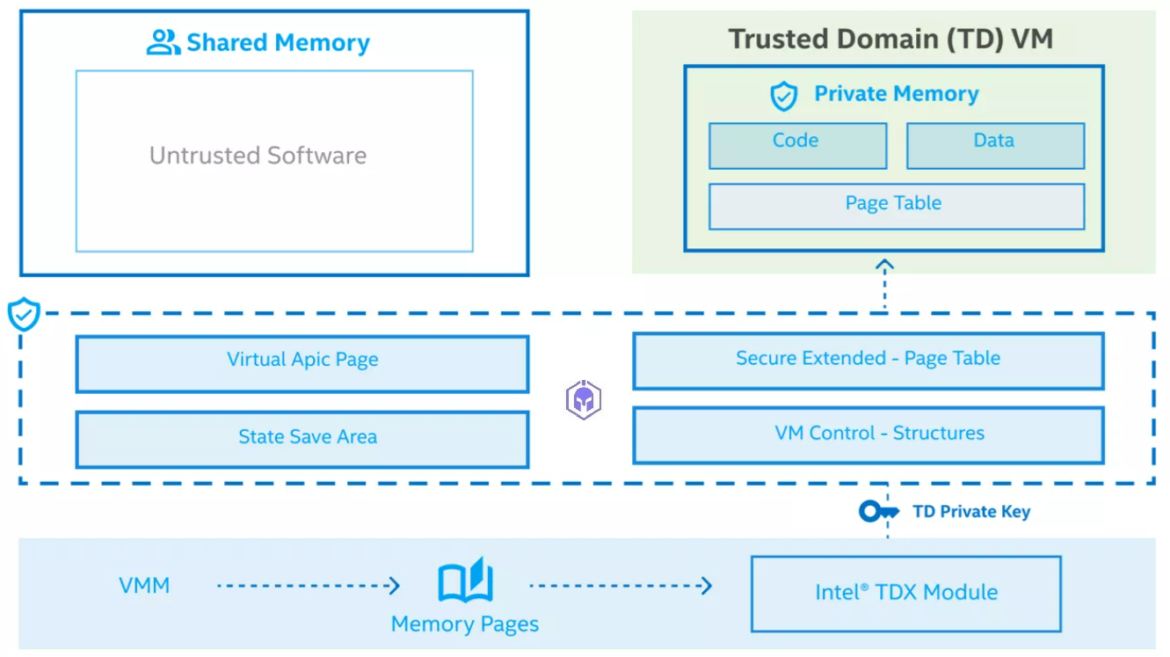
Arm CCA’s vision is centered on “Realms,” which are highly trusted execution environments used by mainstream workloads.Realms are a new type of protected execution environment designed to protect data and/or code from any other execution environments, including hypervisors, OS Kernels, other Realms, and even TrustZone.
Isolation in Arm CCA is managed by the Monitor using the Granule Protection Table (GPT). The GPT is an extension of page tables that controls hardware isolation between the different security states (Non-Secure, Secure, Realm, and Root). The architecture includes a Realm Management Monitor (RMM) that manages Realm-to-Realm protection using stage 2-page tables.
Arm CCA mitigates threats related to confidentiality and integrity loss due to privileged software (Hypervisor/Kernel/Secure world) reading or modifying private Realm memory or register state.
Planned future architecture updates include Device Assignment, which will allow hardware devices (such as accelerators) to be mapped to Realms, and Per-Realm encryption keys to mitigate physical memory replay attacks between Realms.
Confidential computing provides a layered security approach that is critical for mitigating the unique threats facing Generative AI (GenAI) systems and other demanding workloads.
AI Threat Mitigation via TEEs Confidential Computing helps organizations protect proprietary data and models throughout the AI workflow.
Specific threats mitigated by using TEEs include
• Data Theft/Disclosure: TEEs encrypt memory and isolate processing environments, helping ensure sensitive AI data remains secure while actively in use during model training, fine-tuning, and inference.
• Intellectual Property Theft (Model Theft): Confidential computing helps defend against model theft by ensuring the model is processed only in an unencrypted state within the protected memory space of the TEE, guarding against memory scraping and other privileged attacks. This is particularly important for AI models deployed at the edge.
• Model Inversion Attacks: TEEs enforce an attested execution environment where access to the model can be strictly controlled, restricting query types and preventing excessive or abnormal interaction patterns, thereby dramatically reducing the risk of data leakage.
• Data Poisoning: TEEs ensure that training data is processed only within attested, hardware-isolated environments, shielding it from tampering by privileged insiders or malware. This supports data provenance and ensures integrity from data ingestion to model output.
Integrating Accelerators and Performance
Securing AI workload often involves using accelerators, requiring TEEs to collaborate across CPU and GPU domains.
The NVIDIA H100 GPU is a significant development as the first GPU to support TEE. When used in TEE mode, data transfers between the CPU and H100 GPU are encrypted using “bounce buffers,” securing inputs and outputs during transit. To maintain end-to-end security, the H100 works in conjunction with CPU TEEs, such as Intel TDX or AMD SEV-SNP, securing the communication channels.
Performance benchmarks show that while TEE mode on the NVIDIA H100 introduces overhead primarily due to the encryption and decryption during secure data transfer (CPU-GPU I/O via PCIe), this penalty is minimal in high-computation scenarios. The overhead reduces toward zero as the model size grows, due to greater computational demands resulting in longer GPU processing times. For typical Large Language Model (LLM) queries, the overhead remains below 5% for most cases.
Optimizing TEE Memory Usage
For memory-intensive workloads like Deep Learning Inference running in TEEs (such as SGX enclaves) with severe memory constraints, specific optimization techniques are necessary to mitigate high overheads, which can reach up to 26X in unmodified implementations.
1. Page Thrashing Bottleneck Mitigation: The mismatch between enclave size and convolutional-layer memory requirements leads to page thrashing (constant, inefficient transfer of pages). Partitioning schemes address this by applying transformations to a subset of the input array.
• Y-plane partitioning (a novel scheme) divides inputs parallel to the depth direction and is more memory-efficient when the layer output is large.
• Channel partitioning divides the input by channels and is more effective when the weight matrix is large.
• A combination of y-plane and channel partitioning provides the smallest memory footprint and allows large models to be executed efficiently in TEEs as small as 28MB without thrashing.
2. Decryption Bottleneck Mitigation: In fully connected layers, the overhead of secure paging (page decryption and integrity checking) for large weight matrices becomes the dominating performance factor, known as the decryption bottleneck.
Solutions include:
• Quantization: Converting 32-bit float weights into a smaller discrete set (e.g., 16-bit floats) halves the total memory requirements, reducing the amount of data transferred and typically incurring no drop in model accuracy.
• Compression: Using lossy compression can significantly reduce data transfer requirements and proves more efficient than quantization when using a higher number of virtual CPUs to split the decompression workload.
The Spartan AI serves as an AI/ML orchestration platform building trust for existing confidential AI marketplaces and infrastructure providers.
The Platform leverages secure infrastructure to deliver a scalable, enterprise-grade environment for AI, data processing, and mission-critical workloads, ensuring privacy, integrity, and control over sensitive assets.
Building Trust through Orchestration
Confidential computing is at the core of The Spartan AI Platform, ensuring secure, verifiable, and privacy-preserving execution.
Trust is established through several key orchestration steps:
1. Cryptographic Attestation: The Spartan AI guarantees that only authorized workflows are executed by utilizing cryptographic attestation to verify the integrity of the underlying infrastructure. This process confirms that the TEE is genuine, correctly configured, and that the software is exactly as expected. Attestation reports can be requested at any time by the guest VM.
2. Secure Collaboration and Ownership: The Spartan AI combines confidential computing with a decentralized architecture, AI developers and data providers can monetize their assets and collaborate securely while retaining full ownership.
3. Simplified TEE Integration: The Spartan AI provides off-the-shelf infrastructure that abstracts the complexity of confidential computing, allowing users to deploy models instantly in a fully secure environment without requiring expertise in TEEs. The Platform utilizes Confidential VMs for confidential distributed workloads, leveraging built-in support for TEE technologies like Intel TDX/SGX, and AMD SEV, which streamlines the traditionally complex setup process.
4. End-to-End Encryption: The Spartan AI ensures security by combining confidential VMs with hardware TEEs (like NVIDIA H100 GPUs and Intel TDX) to keep prompts encrypted at all times. This configuration protects user data and AI model weights against the infrastructure providers, cloud admins, and external threats.
The Spartan AI Platform utilizes confidential computing and transforms how organizations handle sensitive data, providing the technological basis for trust in AI/ML workloads.
The Spartan built-in support for AMD SEV-SNP, Intel TDX/SGX, and Arm CCA offers hardware-backed isolation, enabling enterprises to innovate confidently with secure AI/ML models.
By mitigating critical threats such as data theft, IP theft, model inversion, and data poisoning, The Spartan AI Platform helps to ensure compliance with stringent privacy regulations.
When integrated into modern public/private environments, The Spartan AI provides the necessary trusted foundation to unlock data silos and accelerate digital transformation while strictly safeguarding the privacy of intellectual property and customer data.
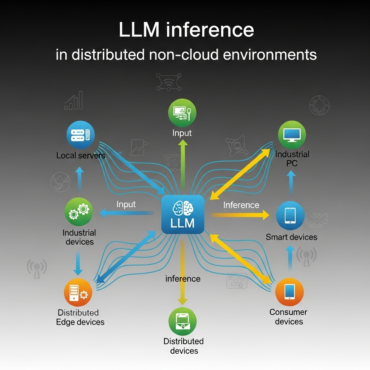
In this article we detail the architecture, implementation, and best practices for serving LLMs in distributed environments, drawing on recent advancements and opportunities. 1. Introduction Large Language Models (LLMs) have ...