Redefining Trust at the Edge The Spartan AI platform utilizes four primary approaches designed specifically for the unique challenges of Edge-AI environments: ✅ Ease of Integration: The platform is designed for “plug-and-play” capability, allowing it to integrate seamlessly into existing enterprise environments. ✅ Continuous On-Chip Machine Learning and Inference: Recognizing that threats [...]
In this article we detail the architecture, implementation, and best practices for serving LLMs in distributed environments, drawing on recent advancements and opportunities.
1. Introduction
Large Language Models (LLMs) have seen an immense surge in popularity since the release of ChatGPT. This has led to a growing demand for LLM-powered applications, which presents significant challenges for deploying and scaling these powerful AI models in production environments. The core issue lies in the substantial computational and memory demands of LLMs, often requiring high-performance GPU servers that can still be strained by the sheer size of the models and the lengthy text sequences they process.
The rapid evolution of this field, with nearly every major system conference featuring dedicated LLM sessions and a particular emphasis on serving systems due to their widespread deployment and the importance of low-latency performance for user experience, makes it difficult for practitioners to stay abreast of developments. This article aims to provide a comprehensive overview of recent advancements in LLM inference, specifically examining system-level enhancements that improve performance and efficiency without altering the core LLM decoding mechanisms. We will highlight key innovations and practical considerations for deploying and scaling LLMs in real-world production environments.
2. Background
There are many types of neural network architectures. In this article we focus on Transformer based architecture.
Transformer-based LLM Architecture
Mainstream LLMs are built on multiple transformer blocks. Each transformer block primarily consists of self-attention-based Multi-head Attention (MHA) operations and Feed-Forward Networks (FFN). Initially, the transformer applies three weight matrices (WQ, WK, WV) to the input X (encoded representation of input text sequence) to compute queries (Q), keys (K), and values (V).
Self-attention is calculated using the formula:
Attention(Q,K, V) = softmax( QKT/√dk )V
For Multi-Head Attention, multiple attention heads (Hi) are computed and then concatenated, followed by a linear projection to produce the final attention result. MHA enables transformers to focus on different parts of the sequence in various representational spaces. Following the MHA block, the normalized output is fed into a position-wise FFN, which consists of two linear transformations with a ReLU activation, further refining the information.
LLM Inference Process
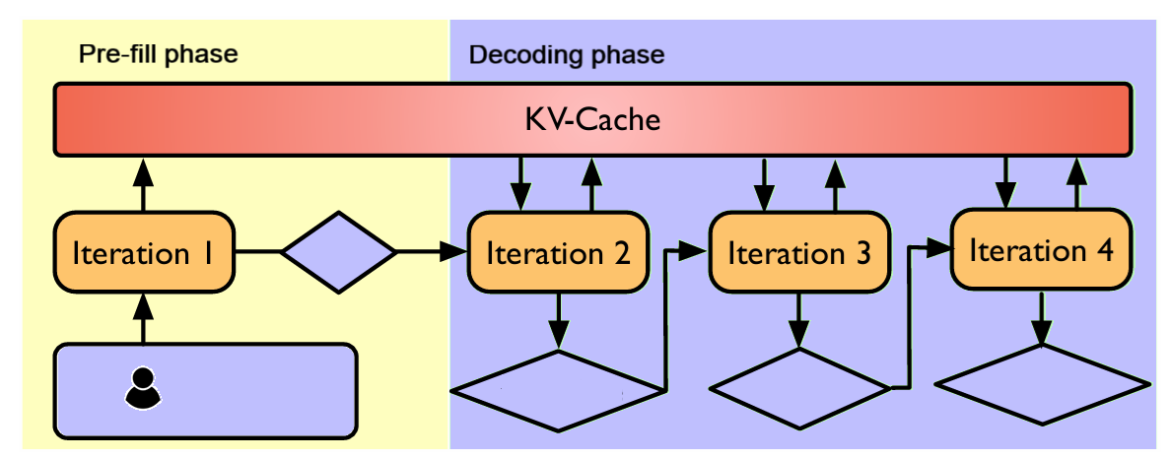
LLM inference generates output tokens autoregressively based on initial input sequences, referred to as Prompts. This process is distinctly divided into two major phases: the prefill phase and the decoding phase.
• Prefill Phase: This phase begins with a tokenized and encoded representation of the prompt passing through the transformer layers. Critically, the generated Key-Value (KV) pairs of all transformer blocks are cached during this phase, forming the KV cache. This caching mechanism is essential as it allows the model to generate subsequent tokens more efficiently without recomputing the KV vectors for all previous tokens.
For an input prompt
P = [p1, p2, …, pn],
a new token Pn+1 is generated, and its K and V are cached as
[(k1, v1), (k2, v2), …, (kn, vn)].
• Decoding Phase: In this phase, the LLM autoregressively predicts and generates new tokens. The newly generated token (pn+1) is appended to the original prompt, and the KV cache is updated. The KV cache grows linearly with the number of tokens generated.
KV Cache Management
A key challenge in LLM serving is managing the KV cache, which grows substantially with the number of generated tokens and can consume a large memory footprint. While model parameters remain constant and intermediate activations are relatively small, efficient KV cache management is crucial for enabling larger batch sizes and processing longer contexts. Modern LLM serving engines employ different strategies to handle this:
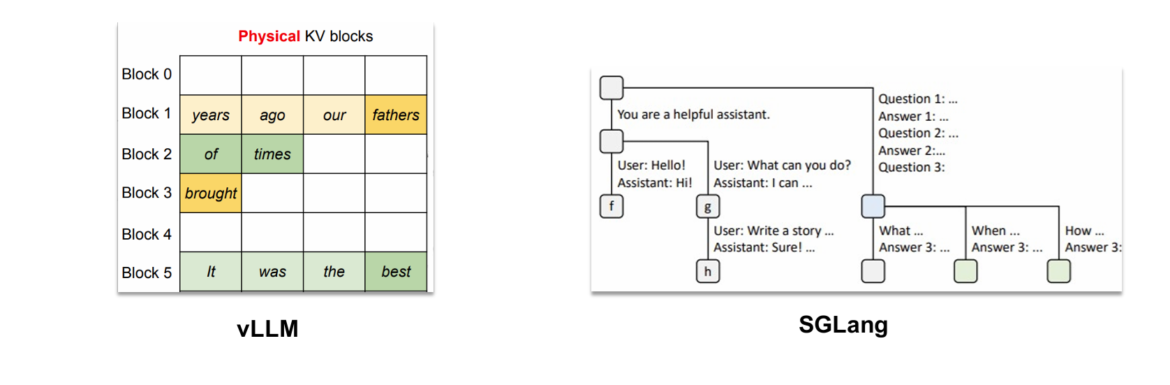
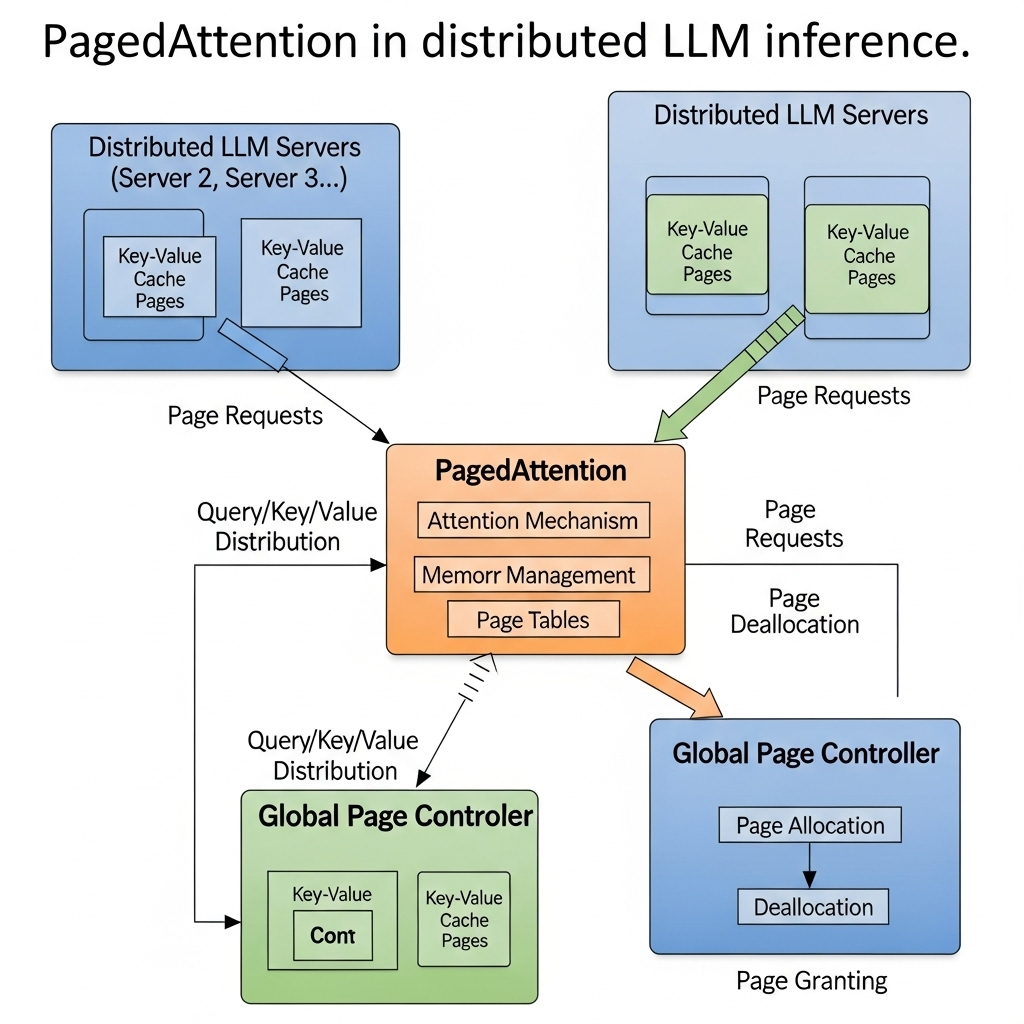
• Paged KV Cache Management: Adopted by systems like vLLM and TGI, this approach is inspired by operating system memory management. It divides the KV cache into non-contiguous memory blocks, each holding a fixed number of tokens, and uses a page table to manage the mapping between tokens and blocks. This significantly reduces memory waste from pre-allocation and fragmentation and enables memory reuse by sharing KV cache blocks across requests with identical prompts. PagedAttention, which implements this, has become an industry norm. • Radix-Tree-Based KV Cache Management: Implemented in systems like SGLang, this method manages the KV cache as a traditional cache, using a radix tree for efficient lookup, insertion, and eviction of KV caches for a given sequence of tokens.
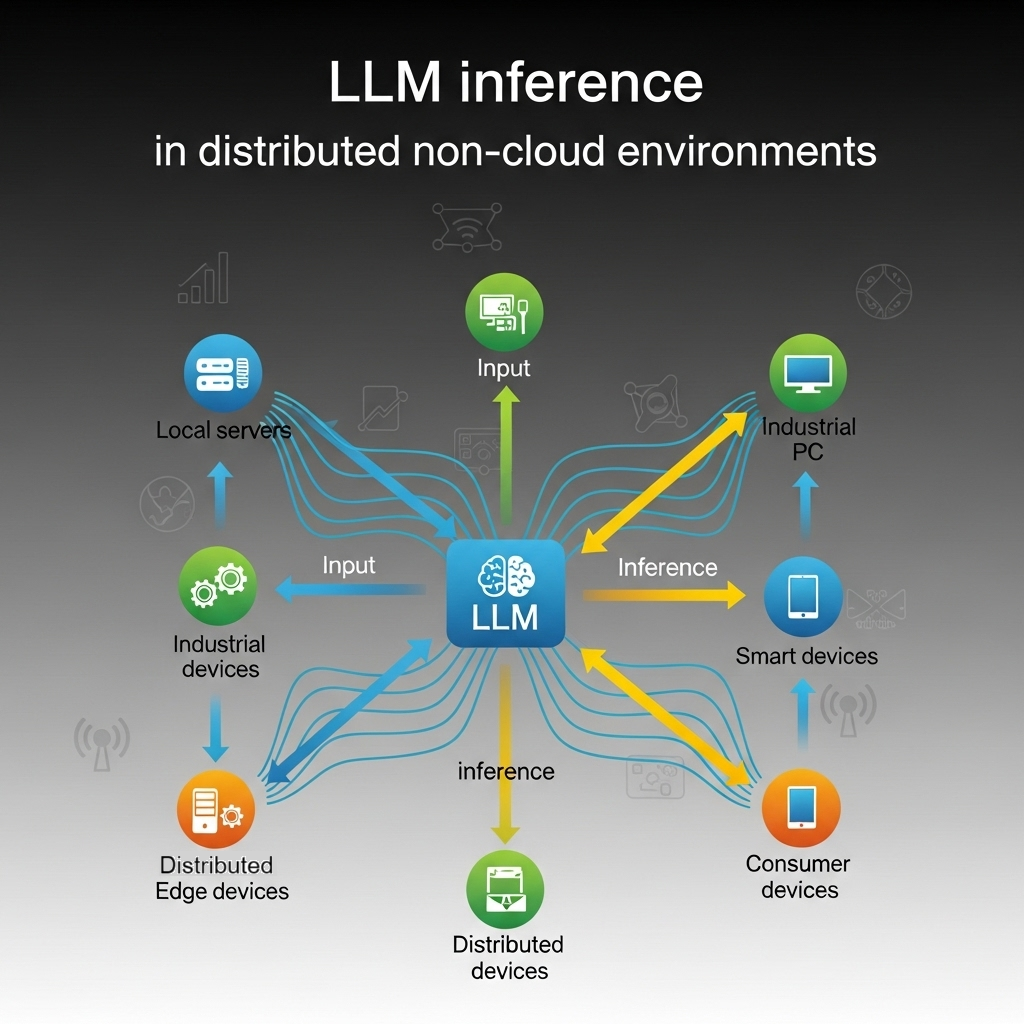
3. Distributed LLM Inference
The increasing scale and intensity of LLM workloads necessitate distributed deployments. Analyzing real-world LLM applications like chatbot services, Retrieval-Augmented Generation (RAG) based Q&A, and offline document processing reveals the need for distributed serving. For example, processing requests from these applications with a small LLM (Llama-34B) on a server with an Nvidia A100 GPU can take several seconds per request (e.g., 3.83s for chatbot, 4.85s for RAG, 2.74s for offline processing).
Given that service providers often need to handle hundreds of requests per second, a single serving engine is insufficient, making distributed clusters vital. A significant opportunity in distributed LLM serving is context reuse. Input prompts often contain recurring segments; for instance, the same documents queried multiple times in knowledge base management, user contexts in personalized assistants, or conversation histories in chatbots.
Modern LLM serving engines can store and reuse the KV cache of these prompts, avoiding redundant computation and drastically improving efficiency. As the scale of distributed LLM deployment grows, the frequency of prompt reuse tends to increase, amplifying the benefits of KV cache reuse. For instance, increasing the KV cache reusing ratio from 0% to 90% in a RAG-based Q&A scenario can reduce average processing time by 2.41×.
Key Challenges
Despite these opportunities, building efficiently distributed LLM serving systems faces several practical challenges:
• KV Cache Eviction: While KV caches are crucial for efficiency, they are large, high-dimensional floating-point tensors (e.g., tens of gigabytes), typically stored in GPU memory for rapid access. However, GPU memory is limited, and KV caches are often evicted quickly (within tens of seconds to minutes) when user sessions become inactive or other active sessions require the High Bandwidth Memory (HBM) space. This necessitates re-computation of the entire KV cache, leading to extra pre-filling costs and reduced efficiency.
• Lack of Fault Tolerance: Distributed clusters are prone to failures. Today’s serving engines generally lack built-in checkpointing or fault tolerance mechanisms. A failure on a node means all running requests are lost, requiring significant time and computation to resume on other engines, impacting overall performance.
• Slow Adaptation to Workload Changes: Real-world request rates can fluctuate by orders of magnitude. Dynamically scaling serving engine instances up or down is challenging because bootstrapping a new instance can take up to ten minutes due to loading hundreds of gigabytes of model weights into GPU memory. This delay can lead to service degradation during peak demand.
Limitations
Existing efforts to improve distributed LLM inference generally fall into two categories but fail to fully address the aforementioned challenges:
• Single instance serving engine optimizations focus on improving efficiency within a single engine through techniques like optimizing GPU kernels, reducing compute complexity, and enhancing request scheduling. While boosting individual performance, these miss the opportunity to reuse contexts across distributed instances.
• Smarter algorithms for request routing treat serving engines as black boxes, attempting to improve KV cache reuse by routing requests to instances with existing caches. However, these are fundamentally limited by the finite, short-lived nature of KV caches held by each isolated serving engine. If KV caches are evicted, routing algorithms become ineffective. Crucially, fault tolerance and elastic scaling challenges remain largely unsolved in these prior approaches.
Decoupling KV Cache from LLMs
A transformative insight for distributed LLM inference is to decouple the internal states (KV cache) from the LLM serving engines. This approach fundamentally changes how serving engines manage their states, turning them into more stateless components.
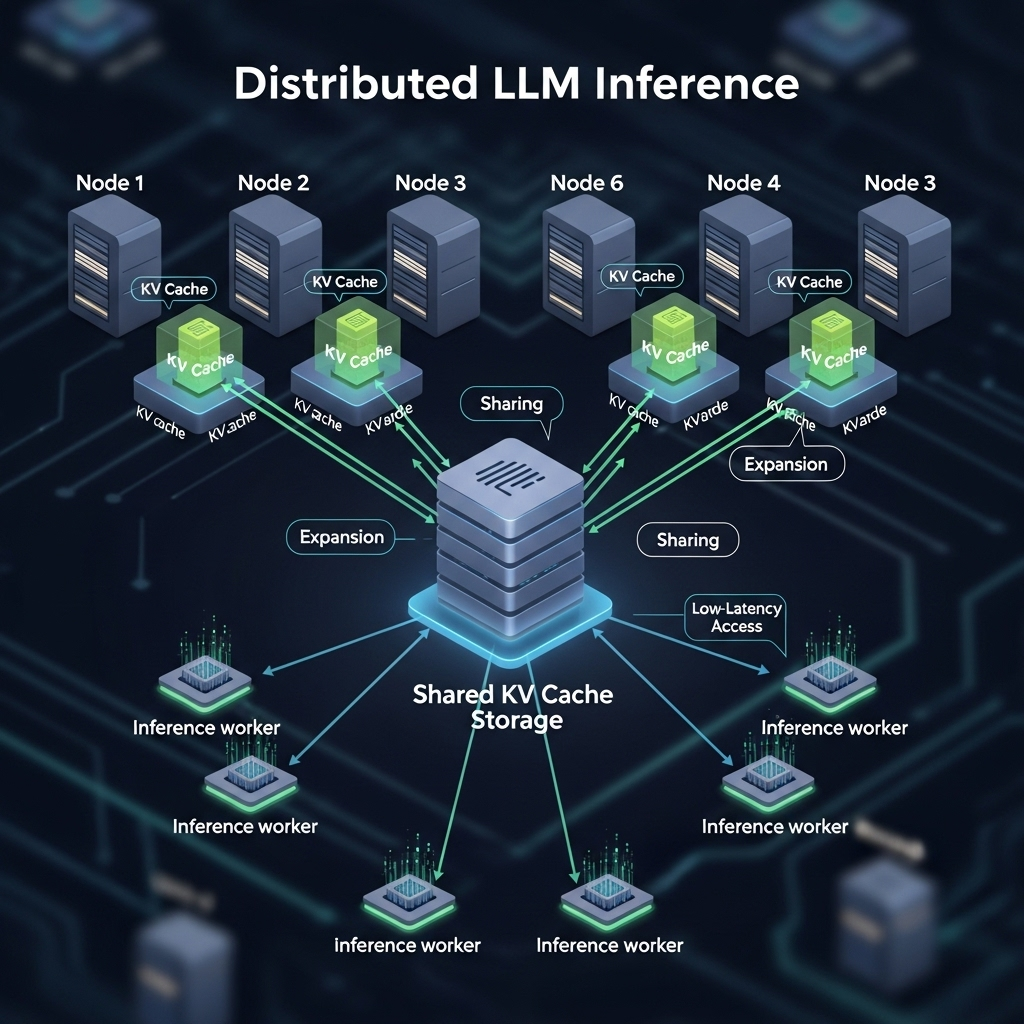
Introducing a separate module to transmit, store, and manage KV caches, distinct from distributed serving engine instances, brings several benefits: • Expanded KV Cache Storage and Sharing: Storing KV caches in a separate module bypasses the limitations of individual GPU memory. This enables global sharing of KV caches across different serving engine instances, creating a larger storage pool that can retain KV caches for extended periods, leading to significantly more reuse.
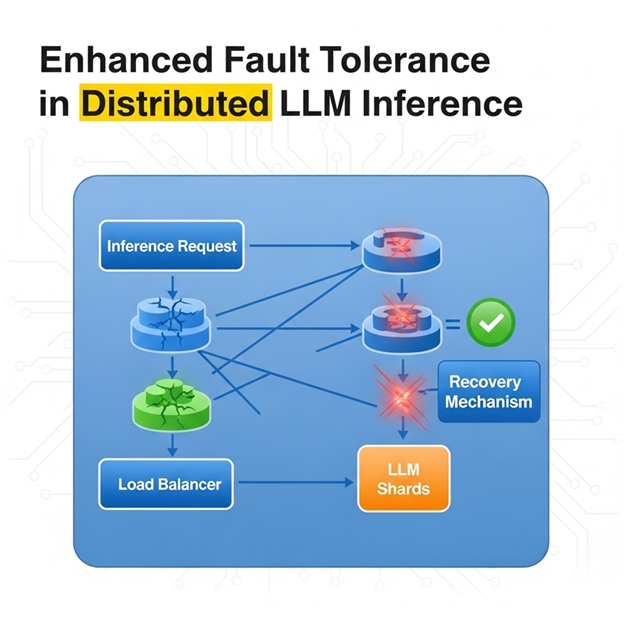
• Enhanced Fault Tolerance: The separate module provides a checkpointing mechanism for processed prompts. If a serving engine fails, other engines can seamlessly resume tasks from the existing KV cache stored in the module, avoiding re-processing the input prompt and reducing computational waste and generation stalls.
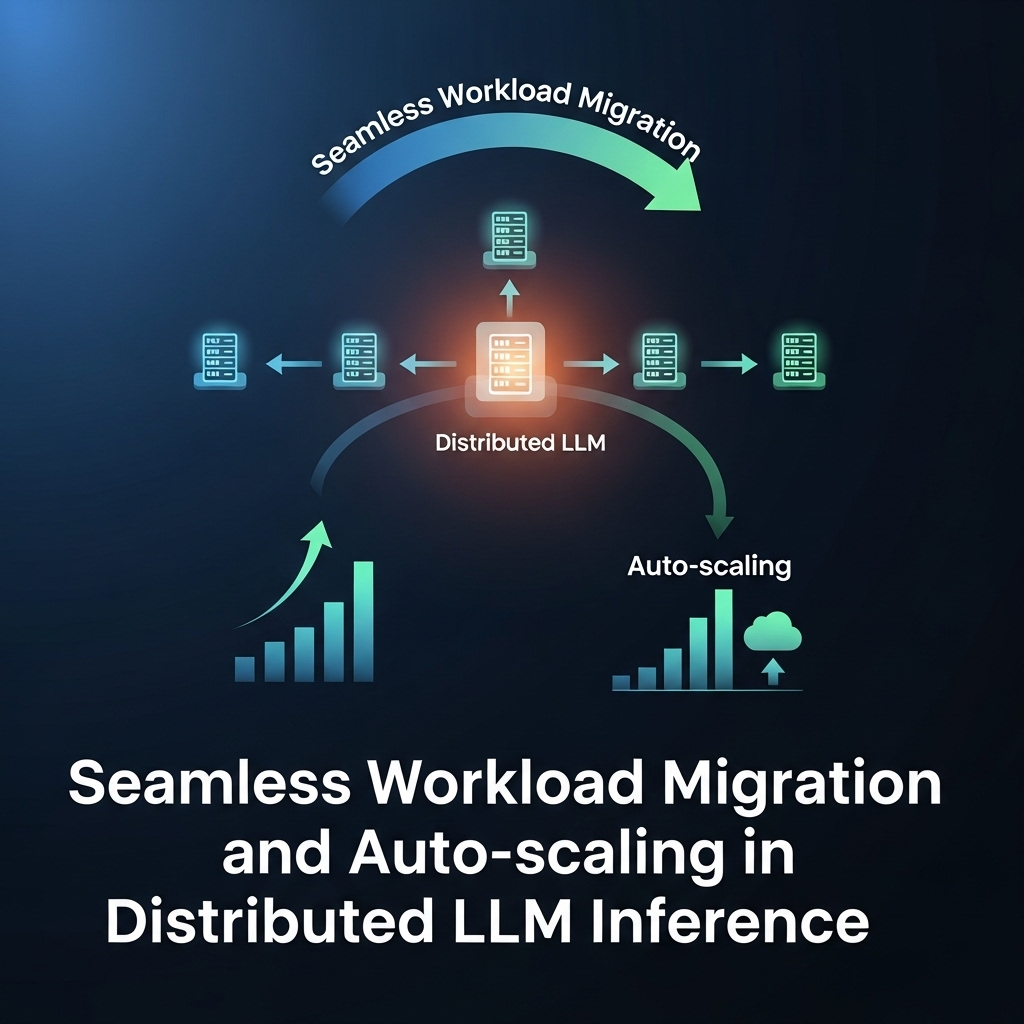
• Seamless Workload Migration and Auto-scaling: This module facilitates seamless workload migration when new serving engines are launched. Newly joined instances can directly take over unfinished work from existing instances, enabling faster adaptation to fluctuating workloads and more efficient auto-scaling by reducing the delay associated with bootstrapping.
4. Review of Existing Distributed Inference options
Recent advancements in LLM serving systems primarily focus on system-level enhancements to improve performance and efficiency without altering the core LLM decoding mechanisms. These innovations can be categorized into several key areas:
KV Cache and Memory Management
Efficient KV cache management is paramount due to its dynamic growth and substantial memory demands.
• Efficient Management of KV Cache:
◦ PagedAttention addresses dynamic KV cache growth by managing it as non-contiguous memory blocks, significantly reducing memory waste and fragmentation compared to contiguous allocation. It has become an industry norm in frameworks like TGI, vLLM, and TensorRT-LLM.
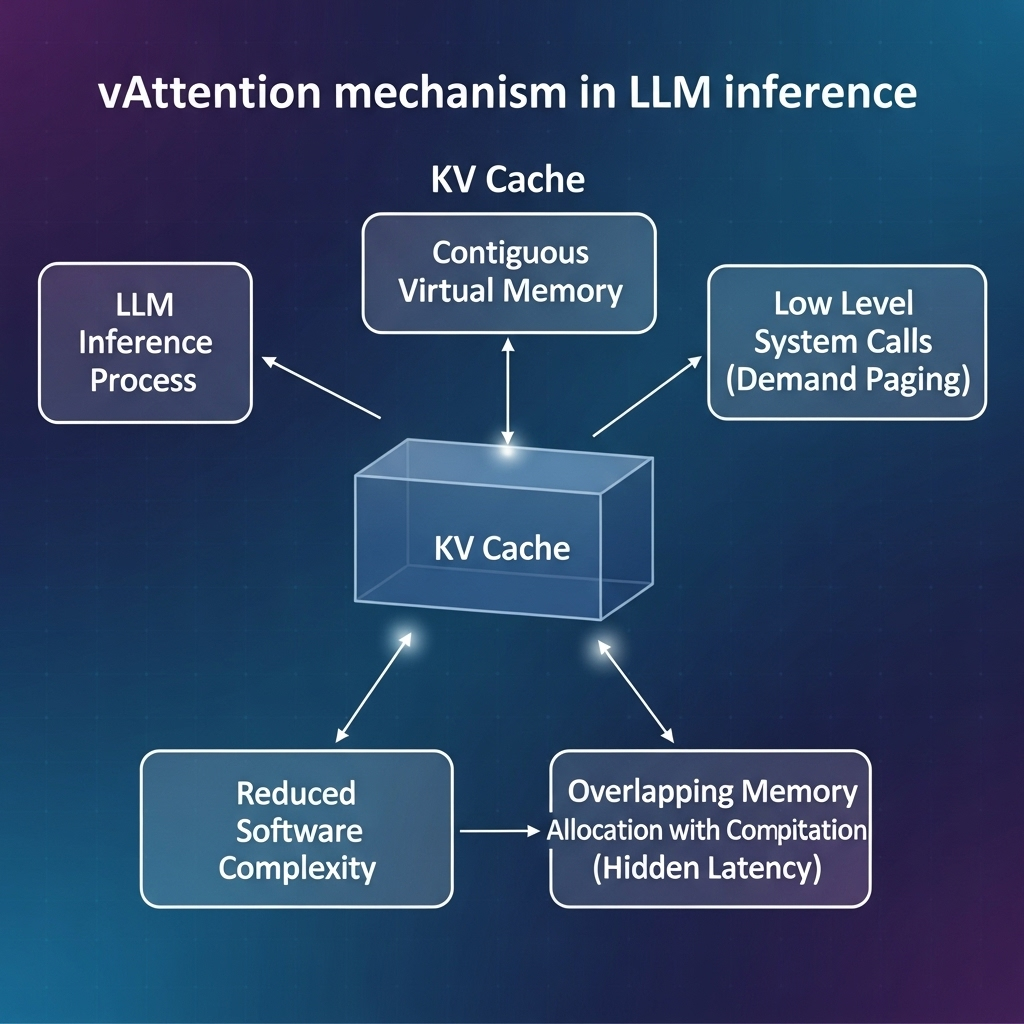
◦ vAttention(virtual PagedAttention) retains the KV cache in contiguous virtual memory by leveraging pre-existing low-level system calls for demand paging, reducing software complexity and overlapping memory allocation with computation to hide latency.
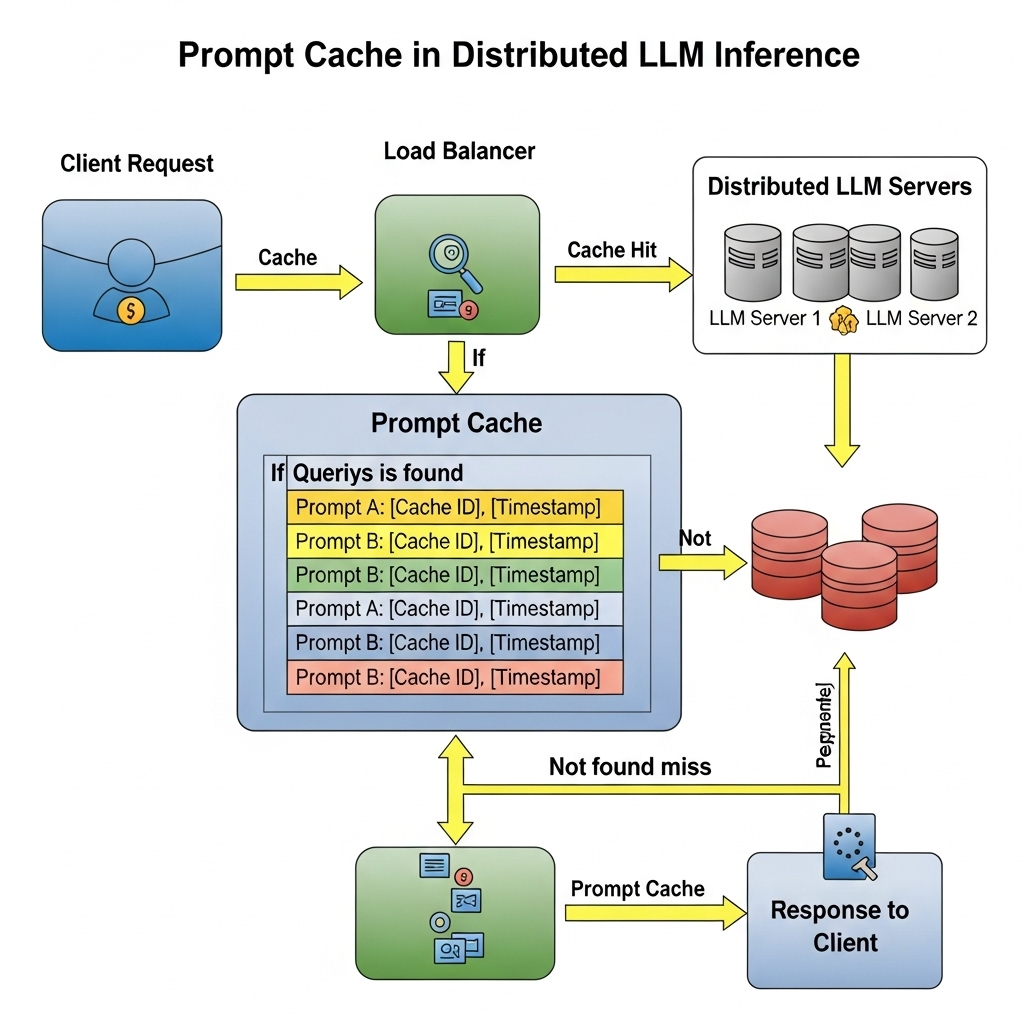
◦ Prompt Cache allows for reusing attention states from pre-defined modules (e.g., system prompts) across multiple requests.
◦ AttentionStore optimizes for multi-turn conversations by utilizing slower storage mediums (CPU memory, disk) and designing intelligent pre-fetching and eviction policies to avoid re-computing KV caches after user session inactivity.
• Support for Long-Context Applications:
◦ Ring attention is a distributed approach that leverages blockwise computation across multiple devices, overlapping KV cache communication with computation to extend context length.
◦ Infinite-LLM is another distributed solution that breaks KV cache into rBlocks across GPUs/CPUs for dynamic memory sharing and coordination.
◦ MemServe unifies inter-request and intra-request optimizations using a distributed memory pool (MemPool) to manage KV cache across a cluster and a global scheduler for reuse.
◦ When GPU memory limits are exceeded, most systems offload KV cache to the CPU. InfiniGen speculates and prefetches only essential KV cache entries to the GPU to reduce data transfer overhead.
◦ LoongServe introduces Elastic Sequence Parallelism (ESP) to dynamically adapt to resource usage and reduce KV cache migration overhead and fragmentation for long sequences.
• Compression of KV Cache:
◦ FlexGen compresses model weights and KV cache to 4 bits using fine-grained groupwise quantization.
◦ KIVI applies asymmetric quantization to key and value caches based on their element distribution, quantizing key cache per-channel and value cache per-token.
◦ Gear achieves near-lossless high-ratio compression by quantizing entries of similar magnitudes and using a low-rank matrix to approximate quantization error.
◦ MiniCache observes high similarity between adjacent KV cache states in middle-to-deep LLM layers, leveraging this to merge them into a shared representation and reduce redundancy.
• Enhancements to KV Cache Management:
◦ KV Cache Offloading Interface: a standard interface to efficiently offload KV caches from serving engines and inject them back. This interface is designed to be agnostic to the serving engine’s internal KV cache management (e.g., vLLM’s paged memory or SGLang’s radix tree) by converting KV cache to a continuous 3-D tensor representation. To minimize performance impact, it utilizes page-locked CPU memory as the destination for offloading, pre-allocates buffers, and uses separate CUDA streams to overlap memory copies with computation.
◦ Knowledge Delivery Network (KDN): KDN is a separate, distributed KV cache management system that addresses the limitations of local KV cache storage. It dynamically compresses, composes, and modifies KV caches to optimize storage and delivery. KDN supports multi-tier storage (GPU, CPU, disk, remote), managing KV caches by chunks and using a storage controller to move them between tiers based on demand and LRU eviction policies.
◦ KV Cache Compression in KDN: KDN implements GPU-based compression techniques inspired by CacheGen, achieving 70-100× speedup compared to CPU-based methods. This makes real-time compression practical for large KV caches, which are millions of times larger than their corresponding text, to overcome bandwidth limitations of slower storage.
◦ Flexible Composition of KV Cache in KDN: KDN integrates techniques like CacheBlend to enable arbitrary composition of different KV caches, even when text segments are not prefix-only (e.g., in RAG or multi-turn chats with system prompts). This significantly enhances KV cache reuse versatility beyond simple prefix matching.
LLM Computation Optimization
Optimizing LLM computation focuses on maximizing resource utilization and execution efficiency.
• Request Batching:
◦ Continuous batching schedules new requests as soon as others complete, boosting GPU core occupancy. This addresses the challenge of variable response lengths that can lead to computational waste with static batching.
◦ DeepSpeed-FastGen uses a dynamic SplitFuse mechanism to decompose long prompts and compose short ones, maintaining high throughput.
• Disaggregated Inference:
◦ This approach separates the prefill and decode phases of LLM inference into independent instances. Systems like TetriInfer, Splitwise, and DistServe leverage the distinct characteristics of these phases (e.g., memory access, compute usage) to prevent interference, allow specialized hardware, and improve utilization. However, prior disaggregation methods had limitations, such as static configurations, intensive data transfer between phases, and a lack of KV cache sharing across prefill instances.
• Model Parallelism:
◦ For LLMs with billions of parameters, model parallel execution across multiple GPUs is necessary.
Enhancements and development
Some areas of research continue to address specific challenges and expand LLM capabilities.
• Retrieval Augmented Generation (RAG):
◦ RAG enhances LLMs by incorporating external information sources to mitigate factual inaccuracies and hallucinations. It involves two stages: retrieval of relevant contexts from a knowledge base and integration into the LLM’s generation process (e.g., concatenation, cross-attention).
◦ Sparse RAG addresses computational overhead from increased input lengths by encoding retrieved documents in parallel and selectively decoding outputs by attending only to highly relevant caches.
◦ RAGCache uses a knowledge tree to cache and share intermediate states of external knowledge across queries, reducing redundant computation.
◦ CacheBlend selectively recomputes a small portion of the KV cache based on preceding text in the input.
• Mixture-of-Experts (MoE) Inference:
◦ MoE models divide into specialized sub-networks (“experts”), with a gating network directing input to the most suitable expert, enabling sparse activation to improve efficiency and performance.
◦ MoE Communication:Lina tackles the all-to-all communication bottleneck in distributed MoE by dynamically scheduling resources based on expert popularity. ExFlow exploits inter-layer expert affinity to reduce cross-GPU routing latency.
◦ Expert Offloading:SiDA-MoE leverages sparsity to exploit both main memory and GPU memory, using a hash-building thread to predict activated experts and dynamically loading/offloading them. MoE-Infinity traces expert activation at the sequence level to predict and prefetch needed experts based on temporal locality. ◦ MoE Efficiency:Fiddler distributes model components (non-expert layers and frequently used experts on GPU, others in CPU memory) to run models on limited GPUs. Huang et al. introduce dynamic gating (varying tokens per expert), expert buffering (caching hot experts in GPU, buffering less active ones in CPU), and expert load balancing.
5. Conclusion
The rapid adoption of Large Language Models (LLMs) and their widespread deployment in diverse applications, RAG-based Q&A, and document processing, have introduced significant challenges in scaling and serving these models efficiently in production environments. The substantial computational and memory demands of LLMs, coupled with the need for low-latency performance and high throughput, necessitate advanced system-level enhancements. While prior research has focused on single-instance optimizations, these approaches often fail to address the unique complexities of distributed LLM deployments, particularly concerning KV cache management, fault tolerance, and dynamic scalability.
This article highlights recent advancements, emphasizing system-level solutions that improve performance and efficiency without altering core LLM decoding mechanisms. The central insight presented is the decoupling of inference states, specifically KV caches, from LLM serving engines. This paradigm shift fundamentally improves distributed LLM inference by allowing for global sharing of KV caches, enabling robust checkpointing for fault tolerance, and facilitating seamless workload migration.
In the next Part2 we’ll review modern implementations of these principles and best practices discussed in this article.
The rapid evolution of Large Language Models (LLMs) has pushed the boundaries of computational demands, making distributed training an indispensable technique. These models, often comprising billions or even trillions of ...