Redefining Trust at the Edge The Spartan AI platform utilizes four primary approaches designed specifically for the unique challenges of Edge-AI environments: ✅ Ease of Integration: The platform is designed for “plug-and-play” capability, allowing it to integrate seamlessly into existing enterprise environments. ✅ Continuous On-Chip Machine Learning and Inference: Recognizing that threats [...]
The rapid evolution of Large Language Models (LLMs) has pushed the boundaries of computational demands, making distributed training an indispensable technique. These models, often comprising billions or even trillions of parameters, frequently exceed the memory capacity of a single GPU, necessitating their distribution across multiple devices and machines. Furthermore, achieving optimal model convergence and throughput often requires large batch sizes, which also contributes to out-of-memory issues. This article provides a comprehensive overview of the approaches, frameworks, and tools employed to address these challenges, alongside insights into GPU programming and advanced parallelization strategies.
1. Introduction to Distributed Approaches, Frameworks and Tools
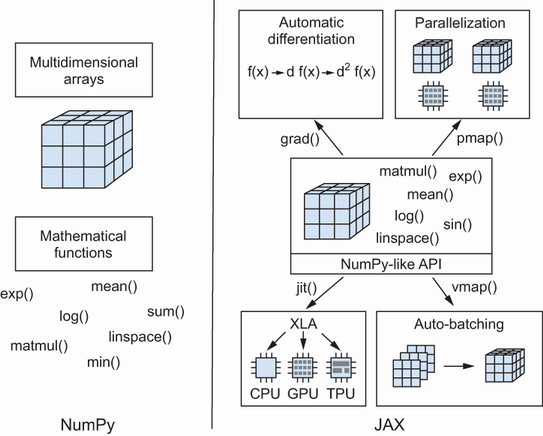
The landscape of deep learning frameworks has seen significant evolution. While TensorFlow v1 was an early dominant player and PyTorch gained popularity for its ease of use, JAX emerged as a powerful Python library developed by Google for deep learning and high-performance computing. JAX, often described as “NumPy on steroids,” is tailored for machine learning and is increasingly relied upon by Google’s research and companies like DeepMind due to its impressive performance on GPUs and TPUs.
JAX’s core strengths for distributed training stem from its functional approach and a set of composable function transformations. These transformations include Just-In-Time (JIT) compilation, auto-vectorization, and parallelization, which provide fine-grained control over low-level processes crucial for efficient model training and inference. This design ethos positions JAX as a “new framework challenger” alongside well-established frameworks like TensorFlow and PyTorch.
The JAX ecosystem is vibrant and rapidly expanding, offering a rich collection of modules and libraries that extend its capabilities across various domains. For LLM training specifically, key members of this ecosystem include:
EasyLM: A one-stop solution for pretraining, fine-tuning, evaluating, and serving LLMs in JAX/Flax, designed to hide the complexities of distributed parallelism while exposing core training details.
Paxml (Pax): A JAX-based machine learning framework by Google for training large-scale models that span multiple TPU accelerator chip slices or pods, focusing on efficient scaling.
MaxText: A simple, performant, and scalable JAX LLM written in pure Python/JAX targeting Google Cloud TPUs, achieving high Model FLOPs Utilization (MFU).
T5X: An older, modular, and composable framework for high-performance training, evaluation, and inference of language sequence models.
Levanter: A framework for training LLMs and other foundation models that prioritizes legibility, scalability, and reproducibility, often used with its companion named tensor library, Haliax.
Jaxformer: A minimal library from Salesforce for training LLMs on TPU in JAX with data and model parallelism.
JaxSeq: Built on Hugging Face’s Transformers library, it enables training LLMs in JAX, supporting various models like GPT2, GPT-J, T5, and OPT.
Alpa: A system for training and serving large-scale neural networks that automatically parallelizes single-device codes on distributed clusters.
Hugging Face Transformers: Officially supports JAX/Flax as a third framework, offering thousands of pretrained models for various NLP tasks, including LLMs and diffusion models.
Distributed training approaches leverage various strategies to overcome memory and computational bottlenecks, including Data Parallelism, Model Parallelism (Tensor Parallelism and Pipeline Parallelism), Expert Parallelism, and Context Parallelism, often combined with ZeRO (Zero Redundancy Optimizer) techniques. These techniques aim to efficiently distribute computations and data across GPU clusters, enabling the training of models that would otherwise be infeasible.
2. Overview of GPU Programming Using CUDA, HIP, OpenCL, Python Distributed Data, JAX, and Triton
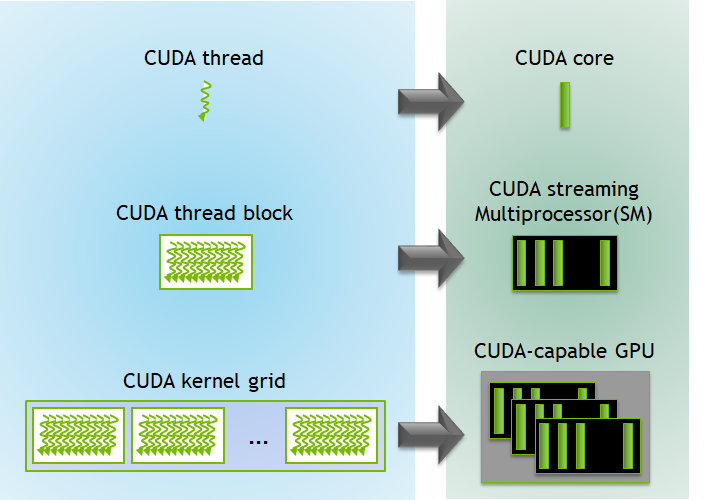
Understanding GPU programming is fundamental to optimizing distributed deep learning. GPUs are characterized by a hierarchical architecture comprising Streaming Multiprocessors (SMs) and numerous cores, along with a multi-layered memory system including Registers, Shared Memory, L1/L2 cache, and Global Memory (High Bandwidth Memory or HBM). The goal of GPU programming is to maximize workload execution in parallel, leveraging this hierarchy.
Low-level GPU Programming Models and Languages:
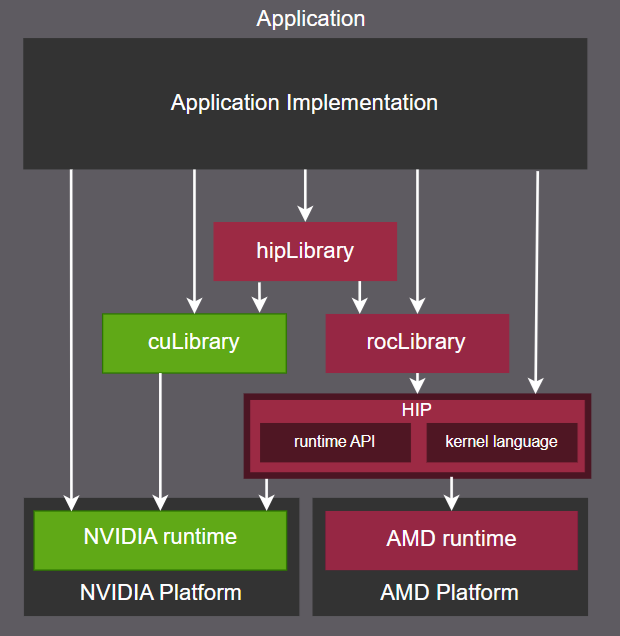
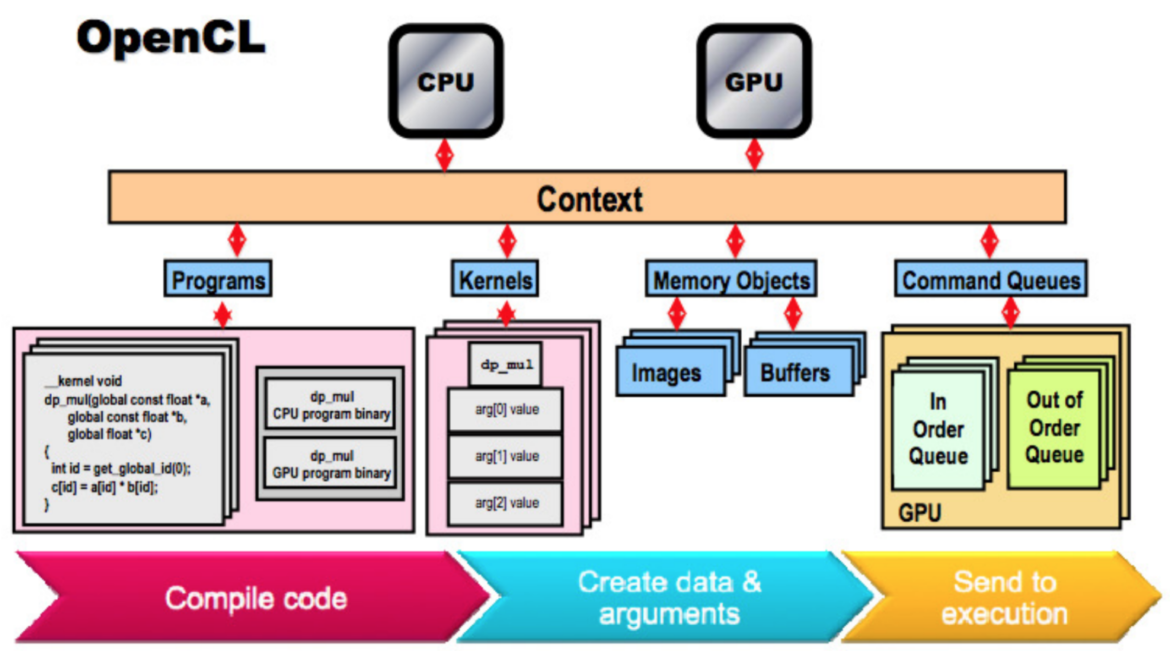
Proprietary Tool-chains: NVIDIA’s CUDA, AMD’s HIP, and Intel’s Level Zero (L0) are hardware-specific low-level programming models. These typically involve C APIs and share common goals such as finding devices, loading/compiling kernels, creating command queues, allocating GPU memory, executing commands (kernel submission, memory copy), and synchronization.
Nvidia CUDA
AMD HIP
Intel Level Zero (L0)
OpenCL: An open standard for parallel programming of heterogeneous platforms. While it offers portability, its adoption by vendors has been lower compared to proprietary solutions.
Kernel Languages: Device-specific code is written in languages like CUDA C/C++, HIP, L0, or OpenCL C, which contain the GPU kernels. These languages impose certain limitations on device code, such as no dynamic allocation, no throw statements, no recursion, and no virtual functions.
Asynchronous Execution: Crucial for performance, allowing the CPU to prepare the next batch of work while the GPU is computing. Synchronization can be fine-grained (via events) or coarse-grained (via barriers).
Memory Allocation: Different types of GPU memory (Device, Shared, Host, Pinned) exist, and memory transfers between CPU and GPU are expensive, making it essential to keep data on the GPU for intensive computations.
Execution Hierarchy: GPU computations are organized into a hierarchy:
NDRange/Grid: Defines the total computation space as a grid of threads.
Work-Group/Block: Divides the NDRange into manageable chunks, with each group operating independently using shared local memory.
Sub-Group/Warp/Wavefront: Smaller units within a work-group that execute in lockstep.
Work-Items/Threads: The fundamental execution units, each with private resources.
JAX's Approach to GPU/TPU Acceleration:
JAX distinguishes itself by leveraging XLA (Accelerated Linear Algebra), Google’s domain-specific compiler. JAX translates Python code into a high-level intermediate representation (Jaxpr), which is then converted to MHLO/StableHLO (MLIR dialects) and finally to HLO for XLA compilation.
JIT compilation (jit() transformation) is a key feature, optimizing computation graphs and fusing sequences of operations into single efficient computations, which significantly improves performance even on CPUs, and especially on GPUs and TPUs.
Pallas: A JAX kernel language that enables writing custom kernels for GPU and TPU, like Triton, allowing for specialized performance optimizations.
Python Distributed Data:
Python-based distributed data libraries often utilize collective operations to manage communication and synchronization between nodes. In PyTorch, these include:
1. dist.broadcast: Sends data from one root node to all other nodes.
2. dist.init_process_group: Sets up the communication backend (e.g., NCCL) and establishes connections between workers.
3. dist.all_reduce: Combines data from all nodes (e.g., summation or averaging) and makes the result available on all nodes.
4. dist.all_gather: Collects data from all nodes and gathers it onto all other nodes.
5. dist.reduce_scatter: Applies a reduction operation to data distributed across nodes and then scatters the results back to the nodes.
6. NCCL (NVIDIA Collective Communications Library) is specifically designed for efficient GPU-GPU communication and is widely used in distributed GPU training.
Triton:
Triton is a GPU compiler built and maintained by OpenAI, enabling developers to write custom GPU kernels. It provides a balance between flexibility and performance, being harder than torch.compile but faster and more flexible, while CUDA offers the highest flexibility and speed but is the most challenging. Custom kernels can optimize memory access patterns, use shared memory, and manage thread workloads efficiently to reduce global memory bottlenecks. A notable example is Flash Attention, which optimizes attention computations by efficiently utilizing GPU memory hierarchy to avoid reliance on slow global memory.
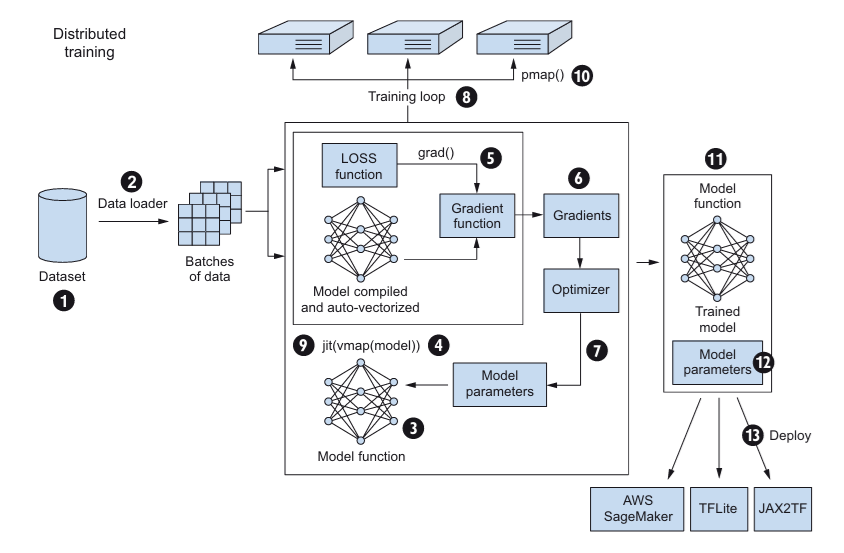
3. Deep Learning Pipelines Using JAX
JAX’s design principles significantly influence the structure of deep learning pipelines, emphasizing a functional programming paradigm. This means that there are no hidden internal states or side effects in JAX functions; instead, all parameters and random number generator states (keys) are explicitly passed as arguments and returned as outputs. This explicit state management promotes code clarity, composability, and reproducibility, which are crucial for complex research and large-scale applications.
Core JAX Transformations for Deep Learning: JAX's power comes from its composable function transformations that allow developers to apply high-level operations to Python functions, automating common deep learning tasks:
grad() for Automatic Differentiation (Autodiff): This transformation takes a numerical function and returns a new function that computes its gradient with respect to its first parameter. JAX supports both forward-mode and reverse-mode autodiff (using jvp() and vjp() respectively), enabling the calculation of not just first-order but also higher-order derivatives, which is critical for advanced optimization and scientific computing.
jit() for Just-In-Time (JIT) Compilation: This transformation compiles Python functions into optimized, high-performance code using XLA. jit() improves performance by optimizing computation graphs, fusing operations, and specializing code for the target hardware (CPU, GPU, TPU).
vmap() for Auto-Vectorization: The vectorizing map transformation converts a function designed to process a single item into one that can efficiently process a batch of items simultaneously. This “auto-batching” simplifies code by allowing developers to write single-example logic without manually handling batch dimensions, while still achieving the performance benefits of vectorized operations on modern hardware. It’s particularly useful for tasks like calculating per-sample gradients.
pmap() for Explicit Parallelization: The parallel map transformation is used to explicitly parallelize computations across multiple devices (e.g., several GPUs or TPUs). It operates in a Single Program, Multiple Data (SPMD) fashion, compiling the function with XLA, replicating it across devices, and executing each replica in parallel. pmap() requires careful management of input and output mapping axes and often uses collective operations (like jax.lax.psum()) for inter-device communication.
Tensor Sharding and jax.Array: A modern and more unified approach to parallelization in JAX is tensor sharding with the jax.Array type. Since JAX computations follow data placement, sharding allows developers to split a tensor across different devices, and JAX's compiler (through jit()) automatically handles the underlying parallel computations and data movement. This enables implicit parallelization, reducing the need for explicit parallel programming constructs.
PositionalSharding and NamedSharding: These objects, often created using mesh_utils.create_device_mesh(), define how tensors are partitioned across a mesh of devices.
replicate(): A method that allows copying tensor slices to each device along a specified dimension, enabling selective replication alongside sharding.
jax.lax.with_sharding_constraint(): Provides hints to the compiler for sharding intermediate tensors, which can further optimize performance.
Pytrees for Complex Data Structures: JAX introduces pytrees as a powerful tool for representing complex nested data structures (e.g., lists of dicts, dicts of arrays). This abstraction simplifies working with neural network parameters, dataset elements, and other hierarchical data common in machine learning. JAX provides utility functions in jax.tree_util for manipulating pytrees:
tree_map(): Applies a function element-wise to the leaves of a pytree.
tree_flatten() and tree_unflatten(): Convert a pytree to a flat list of its leaves and back, respectively.
tree_reduce() and tree_transpose(): Perform reductions and transpositions on pytree structures.
Custom Pytree Nodes: Developers can register their own container classes to behave as pytree nodes, allowing JAX’s utility functions to work correctly with custom data structures.
JAX Ecosystem for Deep Learning Pipelines: For building complete deep learning pipelines, JAX integrates with several higher-level libraries:
Flax: A high-level neural network library by Google that provides familiar abstractions (like nn.Module) for defining neural network layers and architectures. It’s designed to be functional on the outside while allowing stateful definitions internally (e.g., for BatchNorm layers), which is then managed explicitly.
Optax: A library for composable gradient transformations and optimizers, developed by DeepMind. It offers a wide range of state-of-the-art optimizers (e.g., Adam, SGD with momentum) and building blocks for creating custom optimization schemes.
CLU (Common Loop Utils): A library from Google containing common functionalities for writing machine learning training loops and managing metrics, designed to work seamlessly with JAX and Flax.
Orbax: A checkpointing and serialization library oriented towards JAX users, supporting asynchronous checkpointing and various storage formats for models and their states.
4. Distributed LLM Training Using GPU Clusters
Training LLMs on GPU clusters involves navigating significant challenges related to memory limitations and communication overhead. Modern LLMs, with their immense size, require sophisticated parallelization strategies to distribute the model, data, and computations efficiently. The “5D parallelism” paradigm encapsulates these various dimensions: Data Parallelism, Tensor Parallelism, Sequence/Context Parallelism, Pipeline Parallelism, and Expert Parallelism.
4.1.Data Parallelism (DP)
Fundamental technique where the model is replicated on multiple GPUs, and each replica processes a different “micro-batch” of data in parallel. To keep the model replicas in sync, gradients computed on each GPU are averaged using an “all-reduce” operation before the optimization step. A key optimization is to overlap computation and communication, allowing gradient synchronization to occur partially in parallel with the backward pass, significantly speeding up training.
ZeRO (Zero Redundancy Optimizer): Introduced by DeepSpeed, ZeRO addresses the memory redundancy inherent in naive DP (where optimizer states, gradients, and parameters are duplicated on each GPU) by partitioning these components across the data parallel dimension.
ZeRO-1: Partitions only the optimizer states.
ZeRO-2: Partitions both optimizer states and gradients.
ZeRO-3 (Fully Sharded Data Parallelism – FSDP): Partitions optimizer states, gradients, and model parameters, allowing training of models that would not fit into a single GPU. This requires reconstructing parts of the model parameters for forward and backward passes, incurring communication costs.
4.2. Tensor Parallelism (TP)
Involves sharding the model’s large tensors (parameters, gradients, optimizer states, and activations) across devices. This is particularly effective for large layers within a Transformer block, such as Feedforward layers and Multi-Head Attention. For example, a linear layer’s weight matrix can be split, with each GPU computing a portion of the output. TP often requires communication primitives like broadcast and all-reduce within a layer’s forward pass to ensure correctness. While TP reduces memory usage per GPU, it introduces communication overhead that can impact throughput, especially as the parallelism degree increases.
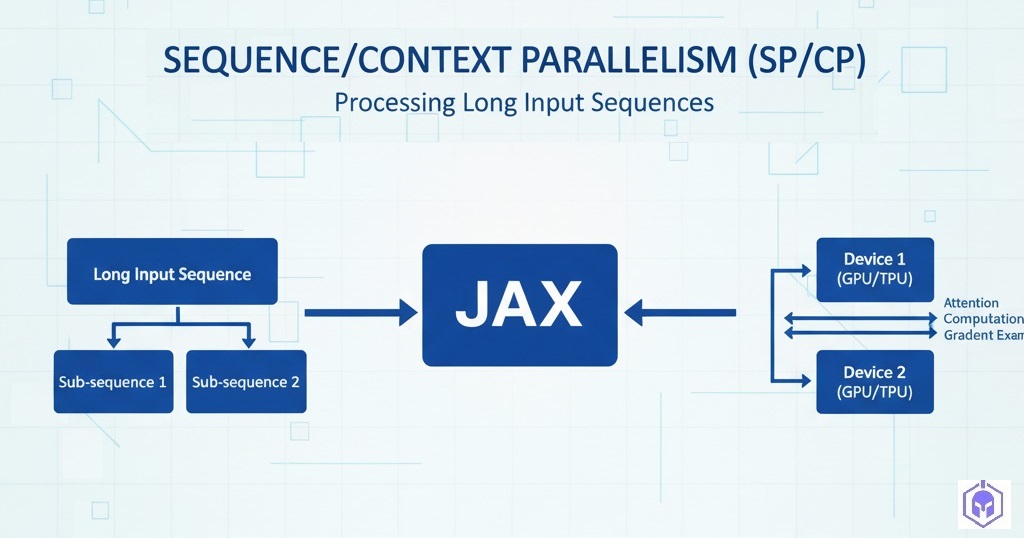
4.3. Sequence/Context Parallelism (SP/CP)
These techniques address the challenge of memory explosion with very long input sequences by sharding activations along the sequence dimension.
Sequence Parallelism (SP): Used in conjunction with Tensor Parallelism, SP specifically handles operations not typically covered by TP (e.g., Dropout and Layer Normalization) by splitting activations along the input sequence dimension. This helps further reduce activation memory, as these operations usually require the full hidden dimension.
Context Parallelism (CP): This approach splits the input sequence dimension across the full model, reducing activation memory for extremely long sequences (e.g., 128k+ tokens). While most modules can process sharded sequences independently, attention layers require full communication to exchange key/value pairs. This is handled efficiently using techniques like Ring Attention, which overlap communication and computation to mitigate the cost.
4.4. Pipeline Parallelism (PP)
Addresses models too large to fit on a single node by splitting the model’s layers across multiple GPUs or nodes. Each GPU stores and processes only a portion of the model, significantly reducing individual GPU memory requirements. However, this introduces a sequential dependency where activations must be passed between GPUs, leading to “bubbles” (idle time) in the pipeline. Various schemes have been developed to reduce these bubbles, including:
Micro-batching: Splitting the batch into smaller portions allows GPUs to process successive micro-batches while others are busy, filling the pipeline.
Interleaving stages: Distributing layers non-sequentially (e.g., odd layers on one GPU, even on another) can balance computation and reduce bubbles.
ZeroBubble and DualPipe: Advanced schedules that minimize idle time by decomposing backward pass operations and using interleaved streams.
4.5. Expert Parallelism (EP)
Specifically designed for Mixture-of-Experts (MoE) architectures, where instead of a single feedforward module, a layer has several independent “experts”. EP places each expert’s feedforward layer on a different worker, enabling parallelism along the experts dimension. Tokens are dynamically routed to the relevant experts, and an all-to-all communication operation is typically used to route tokens and gather results. EP is often combined with Data Parallelism to efficiently shard both experts and input batches.
Mixed Precision Training: A widely adopted optimization technique is Mixed Precision Training, which involves using lower-precision floating-point formats (e.g., float16, bfloat16, and experimental FP8) to reduce memory consumption and accelerate computations. For instance, FP8 matrix multiplications on NVIDIA’s H100 GPUs can achieve twice the theoretical FLOPS of bfloat16. While beneficial, lower precision training, especially FP8, presents stability challenges and can lead to loss divergence, requiring careful analysis and specific quantization schemes (e.g., per-tile normalization) to maintain accuracy.
Custom Kernel Optimization (Flash Attention): Beyond high-level parallelization, low-level optimizations through custom GPU kernels are crucial. Flash Attention is a prime example, significantly optimizing attention computations by making efficient use of the GPU’s hierarchical memory. It avoids materializing large intermediate matrices in slow global memory (HBM) by computing them in small pieces that fit within faster shared memory and registers, thereby reducing memory transfers and alleviating bandwidth bottlenecks. Pallas in JAX and Triton are tools that enable such custom kernel development.
5. Conclusion
The journey to efficiently train Large Language Models on GPU clusters is multifaceted and continually evolving. JAX, with its functional programming paradigm and powerful composable transformations (grad(), jit(), vmap(), pmap(), and tensor sharding), provides a robust foundation for building high-performance deep learning pipelines. Its rich ecosystem, including Flax, Optax, CLU, and Orbax, offers high-level abstractions and utilities that streamline the development process, making complex tasks more accessible.
However, the sheer scale of LLMs necessitates advanced distributed strategies. The “5D parallelism” framework—comprising Data Parallelism (enhanced by ZeRO), Tensor Parallelism, Sequence/Context Parallelism, Pipeline Parallelism, and Expert Parallelism—provides a comprehensive toolkit for distributing models, data, and computations across thousands of GPUs. These techniques address distinct challenges, from memory redundancy to long sequence handling and efficient layer distribution, often requiring careful combinations and optimizations like mixed-precision training and custom kernel development (e.g., Flash Attention) to achieve maximal hardware utilization and throughput. The field remains highly dynamic, with continuous research into new architectures and optimization methods (e.g., FP4 training). Mastering these concepts and tools is crucial for researchers and practitioners aiming to push the boundaries of AI, enabling the training of the next generation of massive and capable models.
The landscape of artificial intelligence is rapidly evolving, with a significant shift from purely cloud-based large language models (LLMs) to more efficient, localized small language models (SLMs) operating on edge ...