Redefining Trust at the Edge The Spartan AI platform utilizes four primary approaches designed specifically for the unique challenges of Edge-AI environments: ✅ Ease of Integration: The platform is designed for “plug-and-play” capability, allowing it to integrate seamlessly into existing enterprise environments. ✅ Continuous On-Chip Machine Learning and Inference: Recognizing that threats [...]
The landscape of artificial intelligence is rapidly evolving, with a significant shift from purely cloud-based large language models (LLMs) to more efficient, localized small language models (SLMs) operating on edge devices. This paradigm shift is driven by the imperative to reduce latency, enhance privacy, lower operational costs, and foster more sustainable AI deployments. By processing data locally, near the source, SLMs are transforming how AI interacts with the real world, from consumer electronics to industrial automation.
1. Landscape of Small Language Models in the current technology world
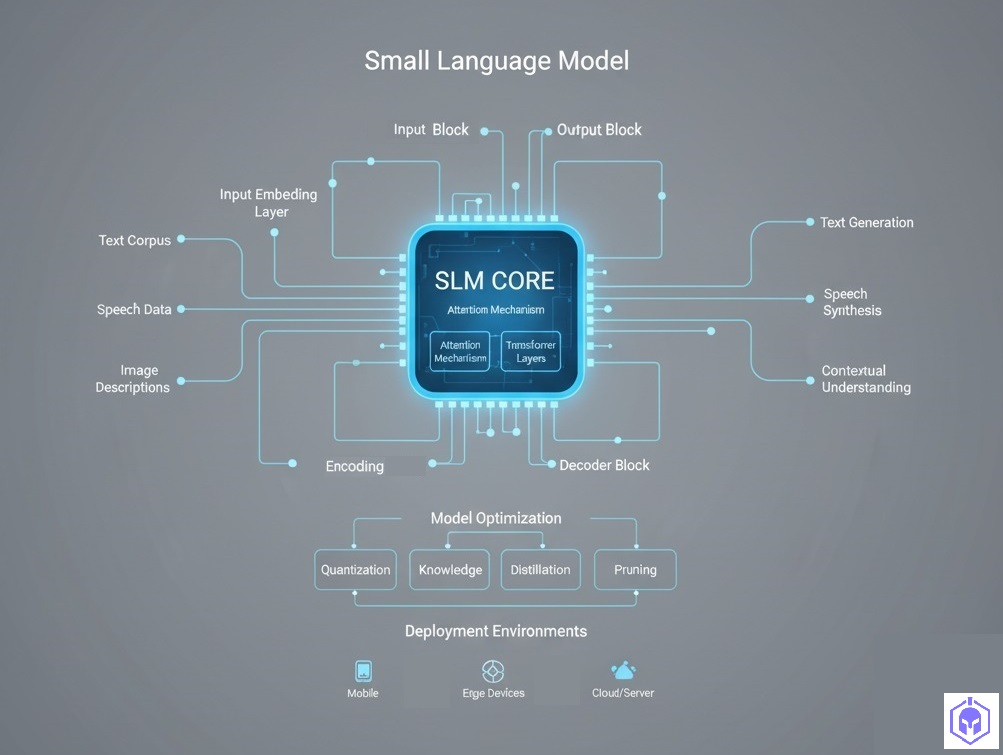
Small Language Models (SLMs) are compact, optimized versions of traditional LLMs, characterized by fewer parameters and streamlined architectures that significantly reduce computational requirements. While a precise parameter counts for “small” can vary, models generally below 10 billion parameters are often considered SLMs. These models are designed for efficiency and can perform inference with low latency on common consumer electronic devices.
The capabilities of SLMs have advanced considerably, now approaching and, in some specialized tasks, even matching or exceeding the performance previously attributed only to much larger models. Recent breakthroughs indicate that the scaling curve between model size and capabilities is becoming steeper, leading to SLMs delivering performance closer to their larger predecessors.
Notable examples of SLMs and their demonstrated capabilities include:
• Microsoft Phi series: Phi-2 (2.7 billion parameters) achieves common sense reasoning and code generation scores comparable to 30-billion-parameter models while running approximately 15 times faster. Phi-3 small (7 billion parameters) demonstrates language understanding and code generation on par with models up to 70 billion parameters.
• Google’s Gemini Nano and Gemma: Gemini Nano is an efficient AI model for Android devices, designed for quick responses, low costs, and strong privacy protection, with support for devices like the Google Pixel 9 and Samsung Galaxy S24 series. Gemma 2 and Gemma 3 achieve remarkable results with around one billion parameters.
• Open models like Mistral and Metalama: These are rapidly closing the performance gap, enabling summarization, translation, and command interpretation directly on-device.
• NVIDIA’s Nemotron-H family and Hymba-1.5B: These hybrid Mamba-Transformer models (2, 4.8, 9 billion parameters) achieve instruction following and code generation accuracy comparable to 30-billion-parameter LLMs at a fraction of the inference FLOPs. Hymba-1.5B outperforms larger 13-billion-parameter models in instruction accuracy and offers 3.5 times greater token throughput than comparable transformer models.
• Huggingface SmolLM2 series: These compact models (125 million to 1.7 billion parameters) match the language understanding, tool calling, and instruction following performance of 14-billion-parameter contemporaries, and even 70-billion-parameter models from two years prior.
• DeepSeek-R1-Distill series: This family of reasoning models (1.5-8 billion parameters) trained on samples from DeepSeek-R1, including the DeepSeek-R1-Distill-Qwen-7B, can outperform large proprietary models like Claude-3.5-Sonnet-1022 and GPT-4o-0513 in commonsense reasoning.
• DeepMind RETRO-7.5B: This Retrieval-Enhanced Transformer model, augmented with an external text database, achieves performance comparable to GPT-3 (175 billion parameters) with 25 times fewer parameters.
• Salesforce xLAM-2-8B: This 8-billion-parameter model achieves state-of-the-art performance in tool calling, surpassing frontier models like GPT-4o and Claude 3.5.
• BERT Mobile: Designed specifically for on-device deployment, BERT Mobile can be pre-trained in the cloud for specific use cases, allowing greater customization and performance gains.
• TinyLlama: A model with 1.1 billion parameters, it can achieve significant speedups on edge devices for tasks like inference.
The aptitude of SLMs for common sense reasoning, tool calling, code generation, and instruction makes them not just viable, but often preferable, for modular and scalable AI systems.
2. Business Cases for Small Language Models
SLMs are highly attractive for a wide range of applications due to their inherent advantages:
• Cost-Efficiency: SLMs significantly reduce operational costs, inference expenses, and energy consumption compared to LLMs. This is particularly valuable in agentic workflows where specialization and iterative refinement are critical.
• Low Latency and Real-time Responsiveness: By enabling processing directly on the device, SLMs eliminate delays associated with cloud-based communication, making them ideal for real-time applications such as robotics, autonomous vehicles, and IoT control systems.
• Enhanced Privacy and Security: Processing sensitive data locally on-device ensures that raw information (e.g., medical transcripts, confidential meetings) never leaves the user’s control, reducing risks of data breaches and helping comply with privacy regulations like GDPR.
• Reduced Bandwidth and Cloud Dependency: Local processing minimizes data transmission to the cloud, which is crucial for applications in low-connectivity environments and enables offline functionality.
• Adaptability and Customization: SLMs are easier and more affordable to fine-tune for specific tasks and evolving user needs. This agility allows behaviors to be added, fixed, or specialized quickly, often requiring only a few GPU-hours for parameter-efficient fine-tuning (PEFT).
• Sustainability: Local inference with SLMs is dramatically more energy-efficient than cloud-based alternatives, supporting greener AI deployment strategies and addressing environmental concerns.
These advantages open numerous practical use cases:
• On-Device Natural Language Processing (NLP): Integrating SLMs into smartphones, smart speakers, and wearables for features like voice assistants, text prediction (e.g., SwiftKey, Gboard), and on-the-fly translation (e.g., Google Translate offline) without cloud connectivity.
• Edge Computing in Diverse Industries:
◦ Healthcare: Real-time diagnostics and rapid decision-making with sensitive patient data, improving outcomes and privacy compliance.
◦ Robotics: Empowering autonomous decision-making, enhancing responsiveness in industrial automation, home assistance, and navigation systems.
◦ Smart Homes and IoT: Interpreting and executing user commands locally, leading to personalized, context-aware responses while conserving energy.
◦ Autonomous Driving: Collaborative inference and real-time video analytics for critical, latency-sensitive applications.
• Agentic AI Systems: SLMs are particularly well-suited for the repetitive, scoped, and non-conversational subtasks within agentic systems, such as tool calling, code generation, summarization, and intent recognition. For instance, a fine-tuned TinyLlama model can act as a voice assistant for a Spotify music player on a Raspberry Pi 5.
• Task Parsing and Automation: Decomposing complex, multi-step user requests into individual, manageable tasks for virtual assistants.
• Classification and Data Extraction: Using SLMs as lightweight parsers for classifying the output of other LLMs or extracting specific details from web pages.
• Personalized Assistants: Developing specialized assistants, such as a gardening assistant fine-tuned on botanical information.
• Grammar and Style Checking: Performing on-device grammar and writing style improvements without uploading requests to the cloud, enhancing privacy.
• Hybrid Cloud-Edge Deployments: SLMs can handle default tasks at the edge, while more complex reasoning or open-domain dialogue can be selectively offloaded to cloud-based LLMs, creating cost-effective and capable heterogeneous systems.
3. Approaches for Provisioning and Deployment of Models at Edge Devices
Deploying SLMs effectively on resource-constrained edge devices requires a combination of model optimization techniques, specialized hardware, and innovative system architectures.
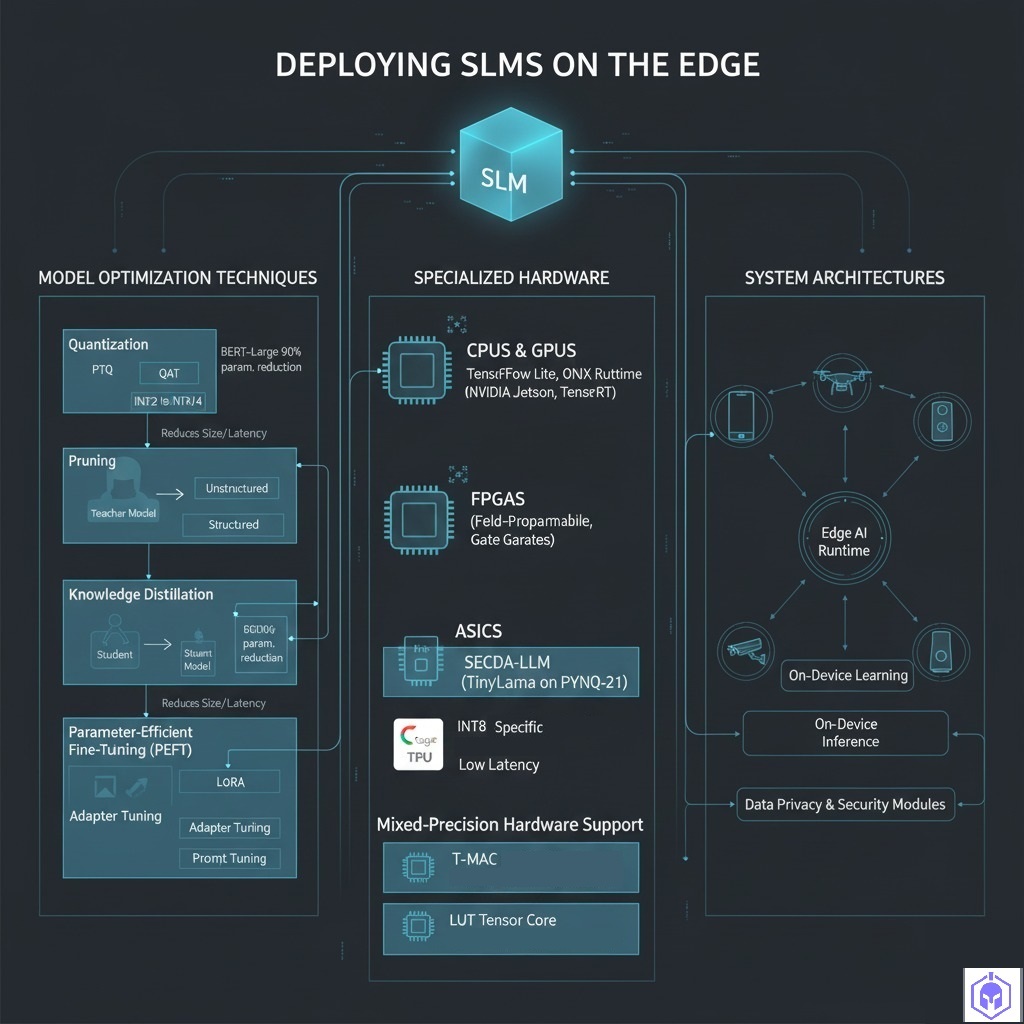
Model Compression and Optimization Techniques:
These methods drastically reduce model footprint and computational load without significant loss in accuracy.
• Quantization: This fundamental technique reduces the numerical precision of model parameters, converting them from high-precision floating-point formats (e.g., FP32) to lower-precision integers (e.g., INT8, INT4). This significantly decreases model size, reduces inference latency, and is highly beneficial for resource-constrained edge devices. Two primary methods exist:
◦ Post-Training Quantization (PTQ): Converts weights after training, requiring no retraining and suitable for quick deployment.
◦ Quantization-Aware Training (QAT): Simulates quantization during training, resulting in superior accuracy but being more resource-intensive.
• Pruning: This complementary strategy identifies and removes unnecessary parameters or neurons from the neural network, reducing complexity and resource requirements.
◦ Unstructured Pruning: Removes individual weights, achieving high sparsity.
◦ Structured Pruning: Removes entire neurons, channels, or layers, directly reducing computational overhead and being hardware friendly. Google’s BERT-Large, for instance, showed a 90% parameter reduction with minimal accuracy loss.
• Knowledge Distillation: Training a smaller “student” model to mimic the behavior of a larger “teacher” model, effectively transferring knowledge and reducing the student model’s size.
• Parameter-Efficient Fine-Tuning (PEFT): These approaches adapt SLMs with minimal overhead by updating only small subsets of model parameters, enabling rapid adaptation to new tasks or environments. Key strategies include:
◦ Low-Rank Adaptation (LoRA): Introduces low-rank matrices to pretrained models, fine-tuning new tasks by adjusting typically less than 1% of original parameters.
◦ Adapter Tuning: Inserts small neural network layers (adapters) into a pretrained model, with only adapter parameters updated during fine-tuning.
◦ Prompt Tuning: Modifies model behavior with minimal updates by training only a small set of additional parameters representing “prompts”.
Hardware Accelerators and Device-Specific Implementations:
Effective deployment leverages hardware capabilities to ensure computational efficiency and minimal latency.
• CPUs and GPUs: Optimizations for general-purpose processors.
◦ CPU-Based Optimization: Benefits from vectorization, efficient multithreading, and cache-aware programming. Frameworks like TensorFlow Lite and ONNX Runtime are optimized for ARM-based CPUs found in devices like Raspberry Pi.
◦ GPU-Based Optimization: Devices like NVIDIA Jetson Nano utilize GPU parallelism. Optimizations include TensorRT integration for GPU-specific quantization and operator fusion, and memory management to prevent exhaustion.
• FPGAs (Field-Programmable Gate Arrays): Offer custom parallelism and adaptive precision, making them suitable for scenarios demanding customization, low latency, and energy efficiency. The SECDA-LLM platform, for example, streamlines the design, integration, and deployment of FPGA-based LLM accelerators for edge devices, showing an 11x speedup over CPU-only inference for the TinyLlama model on a PYNQ-Z1 board.
• ASICs (Application-Specific Integrated Circuits): Provide highly specialized performance optimizations. Google’s Edge TPU is designed for efficient INT8 quantized models, dramatically reducing memory footprint and inference latency.
• Mixed-Precision Hardware Support: Most hardware supports symmetric computations, but advancements like mixed-precision matrix multiplication (mpGEMM) are becoming viable. Microsoft Research’s efforts address this with:
◦ Ladder data type compiler: Converts unsupported data types into hardware-compatible ones without data loss, generating high-performance conversion code.
◦ T-MAC mpGEMM library: Implements General Matrix Multiplication (GEMM) using a lookup table (LUT) approach, eliminating multiplications to significantly reduce computational overhead. It delivers several times the speed of other libraries on diverse CPUs.
◦ LUT Tensor Core hardware architecture: A cutting-edge design for next-generation AI hardware, specifically tailored for low-bit quantization and mixed-precision computations, achieving 6.93 times inference speed while using only 38.3% of the area of a traditional Tensor Core.
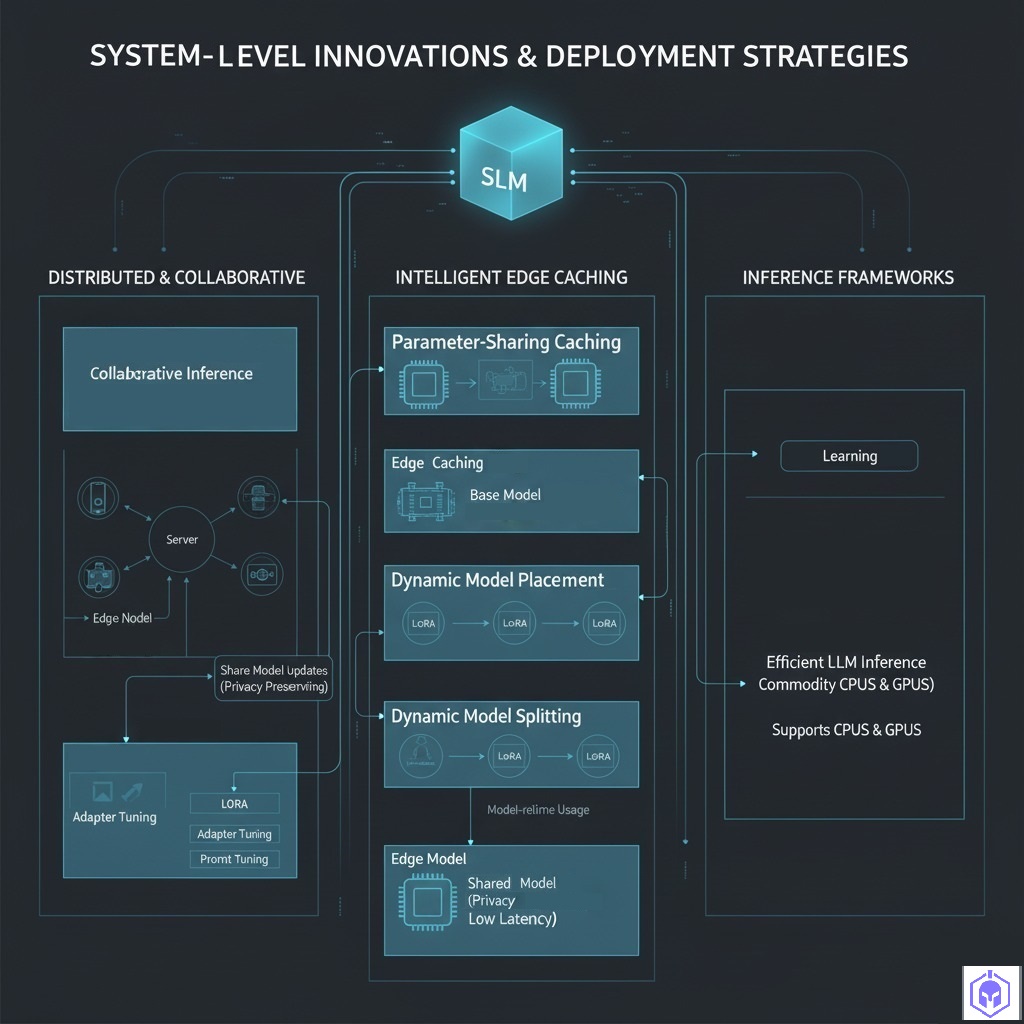
System-Level Innovations and Deployment Strategies:
• Distributed and Collaborative Approaches: Given resource limitations, methods balancing workloads among edge devices and centralized servers are crucial.
◦ Collaborative Inference: Splits inference workload, with edge nodes handling initial processing and complex computations offloaded to servers.
◦ Federated and Split Learning: Facilitate distributed training across edge devices, sharing only model updates to preserve data privacy. Split Learning divides the model between device and server.
• Intelligent Edge Caching and Parameter Sharing: Optimizes bandwidth and storage.
◦ Parameter-Sharing Caching: Stores common model components once, reducing storage demands, especially for LoRA fine-tuned models which can share up to 99% of parameters.
◦ Dynamic Model Placement and Adaptive Caching: Moves frequently accessed models closer to users and adjusts cached components based on real-time usage.
◦ Multi-Hop Model Splitting and Distribution: Distributes large SLMs across interconnected edge nodes for collaborative inference, balancing workload in extended IoT environments.
• Inference Frameworks: C/C++ libraries for efficient LLM inference on a wide range of hardware, including commodity CPUs and GPUs, supporting various block floating-point (BFP) quantization levels.
4. Roadmap and Future Development
The future of SLMs at the edge is characterized by continuous innovation aimed at overcoming existing challenges and expanding their applicability across diverse scenarios.
Overcoming Challenges:
• Computational and Energy Limitations: Future work will focus on making SLMs even more adaptive, energy-efficient, and context-aware. This involves continued research into adaptive model architectures, contextual sparsity prediction, and speculative decoding techniques. The goal is to select models that are “good enough” for the job, rather than always deploying the largest ones.
• Hardware Heterogeneity and Ecosystem Fragmentation: A major hurdle is the lack of standardization across diverse edge hardware platforms, operating systems, and capabilities. The roadmap includes developing lightweight countermeasures that can be easily deployed across these varied devices, ensuring interoperability, and standardizing communication protocols and model formats.
• Security and Privacy: Edge AI introduces new attack vectors and aggravates existing ones due to its distributed nature and lack of central control. Future research must develop robust models resilient to data poisoning, backdoor attacks, and inference attacks. This includes improving private approaches that balance privacy with model accuracy and investigating scalable solutions that go beyond trusted intermediaries. Secure collaborative learning and inference mechanisms are crucial when there isn’t a single central entity controlling the training or inference process.
• Ethical Decision-Making: As AI applications at the edge become more prevalent in sensitive areas like healthcare or surveillance, developing frameworks to align AI decisions with ethical guidelines and societal norms is paramount. This includes addressing issues such as representational bias, toxicity, malicious instructions, hazardous behaviors, and value misalignment, which are often exacerbated in edge deployments due to lack of control over infrastructure and inputs.
• Model Compatibility and Scaling: Understanding the trade-offs between model size, latency, and accuracy for various architectures remains critical. Research is also needed into secure infrastructure for managing and updating models on edge devices, especially via over-the-air (OTA) updates.
Future Developments:
• SLM-First Architectures: The industry is trending towards SLM-first architectures, where SLMs are used by default for agentic tasks, and LLMs are invoked selectively for general reasoning or complex dialogues. This modular approach combines the efficiency of SLMs with the generality of LLMs.
• Agentic AI Transformation: SLMs are considered the future of agentic AI, driving a transformative effect on white-collar work and beyond. The ability to convert LLM-based agents to SLM specialists through processes like usage data collection, data curation, task clustering, SLM selection, and specialized fine-tuning is a key enabler. This allows for a continuous improvement loop, where agentic interactions themselves become a source of data for future model enhancement.
• Democratization of AI: By removing the infrastructure barriers traditionally associated with AI, SLMs will democratize intelligence, enabling startups and Original Equipment Manufacturers (OEMs) to embed meaningful AI in nearly any device, from thermostats to factory robots.
• Increased Computational Density and Energy Efficiency: Innovations like the LUT Tensor Core are expected to drive a paradigm shift in AI model inference, offering higher transistor density, greater throughput per chip area, lower energy costs, and better scalability than traditional multiplication-accumulation operations.
• Open-Source Contributions: Platforms like T-MAC and Ladder are already open source, inviting broader testing and exploration of these innovations. In conclusion, the deployment of SLMs at the edge presents a compelling vision for the future of AI. While challenges related to computational constraints, security, privacy, and ethical considerations persist, ongoing research and development in model optimization, hardware acceleration, and decentralized architectures are steadily paving the way for ubiquitous, efficient, and responsible edge AI. This shift will unlock new classes of real-time, personalized, and sustainable AI experiences, delivered directly from devices rather than distant data centers
In the upcoming Part 2 we’ll describe a clear and straightforward picture how The Spartan AI Platform adds value to SLMs orchestration for Edge AI and Agent business cases.
When private users and businesses use Cloud LLMs, the following processes run behind the scene: Scared sharing personal, business data to Cloud LLMs and loosing control on your core Knowledge ...